RAGAS RAG 评测#
RAGAS(Retrieval Augmented Generation Assessment)是一个专门评测检索增强生成(RAG)系统性能的框架。核心评测指标包括:
指标 |
含义 |
|---|---|
Faithfulness(忠实性) |
生成答案是否基于检索到的上下文,无虚构内容 |
AnswerRelevancy(答案相关性) |
生成答案是否直接回应了用户问题 |
ContextPrecision(上下文精准度) |
检索到的上下文中相关信息的占比 |
ContextRecall(上下文召回率) |
回答所需信息是否被完整检索到 |
AnswerCorrectness(答案正确性) |
生成答案与标准答案的一致程度 |
此外,RAGAS 还支持自动从文档生成测试数据集,以及多模态图文 RAG 评测。
环境准备#
pip install evalscope[rag] -U
场景一:用现有数据集评测 RAG(Quick Start)#
适用于:已有 question/answer/context 数据,想快速评测 RAG 系统质量。
数据格式#
评测数据为 JSON 文件,每条记录包含以下字段:
字段 |
说明 |
|---|---|
|
用户问题 |
|
RAG 系统生成的答案 |
|
检索到的上下文列表 |
|
标准答案(ground truth) |
示例:
[
{
"user_input": "第一届奥运会是什么时候举行的?",
"retrieved_contexts": [
"第一届现代奥运会于1896年4月6日到4月15日在希腊雅典举行。"
],
"response": "第一届现代奥运会于1896年4月6日举行。",
"reference": "第一届现代奥运会于1896年4月6日在希腊雅典开幕。"
}
]
配置与运行#
from evalscope.run import run_task
eval_task_cfg = {
"eval_backend": "RAGEval",
"eval_config": {
"tool": "RAGAS",
"eval": {
"testset_file": "outputs/testset.json",
"critic_llm": {
"model_name": "Qwen/Qwen2.5-72B-Instruct-GPTQ-Int4",
"api_base": "http://127.0.0.1:8000/v1",
},
"embeddings": {
"model_name_or_path": "AI-ModelScope/m3e-base",
},
"metrics": [
"Faithfulness",
"AnswerRelevancy",
"ContextPrecision",
"AnswerCorrectness",
],
"language": "chinese",
},
},
}
run_task(task_cfg=eval_task_cfg)
结果解读#
评测完成后,输出结果如下所示:
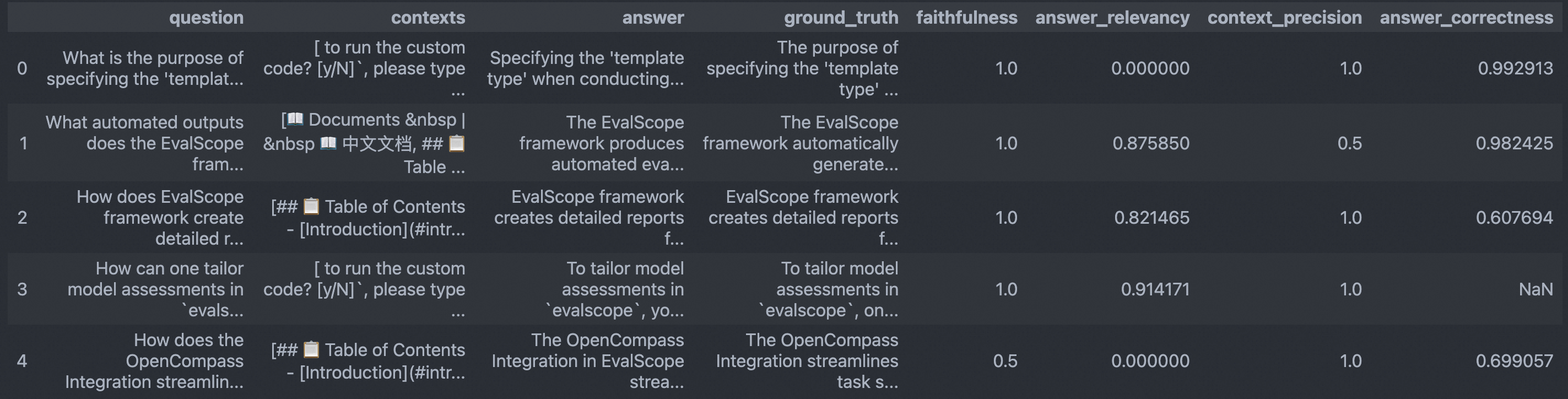
评测结果#
每条数据将附带各指标得分,整体报告展示所有指标的平均分。
该场景关键参数#
参数 |
类型 |
默认值 |
说明 |
|---|---|---|---|
|
|
- |
评测数据集文件路径 |
|
|
- |
评测用 LLM 配置(详见参数参考) |
|
|
- |
嵌入模型配置(详见参数参考) |
|
|
|
评测指标列表 |
|
|
|
语言设置,中文评测设为 |
|
|
|
批量大小 |
场景二:自动生成测试数据集#
适用于:没有现成的评测数据,想从已有文档自动生成 question/answer/context 测试集。
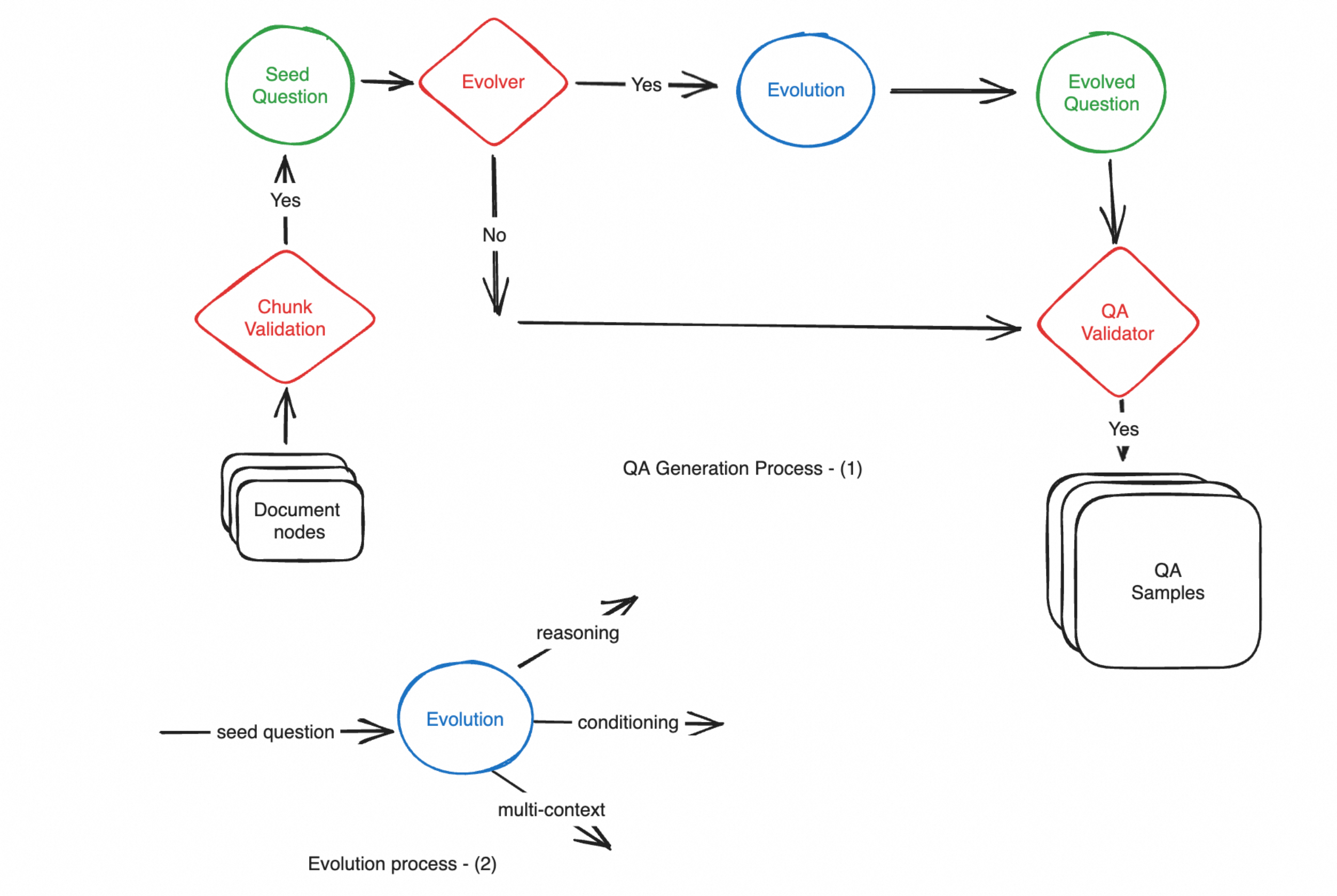
RAGAS 采用进化生成范式,受 Evol-Instruct 启发,从文档中系统性地构建不同特征的问题(推理、条件、多上下文等),确保评测覆盖全面。#
准备文档#
将待生成测试数据的源文档准备好(支持 markdown、txt 等格式)。文档内容应足够丰富(建议 > 100 tokens),否则可能报错。
配置与运行#
from evalscope.run import run_task
generate_testset_task_cfg = {
"eval_backend": "RAGEval",
"eval_config": {
"tool": "RAGAS",
"testset_generation": {
"docs": ["README_zh.md"],
"test_size": 10,
"output_file": "outputs/testset.json",
"generator_llm": {
"model_name": "Qwen/Qwen2.5-72B-Instruct-GPTQ-Int4",
"api_base": "http://127.0.0.1:8000/v1",
},
"embeddings": {
"model_name_or_path": "AI-ModelScope/m3e-base",
},
"language": "chinese",
},
},
}
run_task(task_cfg=generate_testset_task_cfg)
生成完成后,数据将保存到 output_file 指定路径,格式与场景一的输入格式相同。
该场景关键参数#
参数 |
类型 |
默认值 |
说明 |
|---|---|---|---|
|
|
- |
源文档路径列表 |
|
|
|
生成测试集的条目数 |
|
|
|
生成数据集的输出路径 |
|
|
- |
生成器 LLM 配置(详见参数参考) |
|
|
- |
嵌入模型配置(详见参数参考) |
|
|
|
语言设置,如 |
故障排除#
LLM 输出格式错误
备注
generator_llm 需要指令遵循能力较强的模型。7B 及以下规模的模型可能出现如下错误:
ragas.testset.transforms.engine - ERROR - unable to apply transformation: 'Generation' object has no attribute 'message'
这是因为小模型输出格式不符合预期,导致解析失败。解决方案:使用更大规模的模型(如 Qwen/Qwen2.5-72B-Instruct-GPTQ-Int4)或闭源模型(如 GPT-4o)。
文档过短
小技巧
若出现以下错误,说明 unstructured 库处理文档时内容不足:
ValueError: Documents appears to be too short (ie 100 tokens or less). Please provide longer documents.
解决方案:确保源文档内容充足,或将文档预处理为纯 txt 格式后重试。
场景三:多模态图文 RAG 评测#
适用于:评测包含图片理解能力的 RAG 系统,上下文中可能包含图片。
数据格式#
与场景一的数据格式相同,区别在于 retrieved_contexts 中可以包含图片路径(本地路径或网络 URL):
[
{
"user_input": "图片中的汽车品牌是什么?",
"retrieved_contexts": [
"custom_eval/multimodal/images/tesla.jpg"
],
"response": "特斯拉是一个汽车品牌。",
"reference": "图片中的汽车品牌是特斯拉。"
}
]
配置与运行#
from evalscope.run import run_task
multi_modal_task_cfg = {
"eval_backend": "RAGEval",
"eval_config": {
"tool": "RAGAS",
"eval": {
"testset_file": "outputs/testset_multi_modal.json",
"critic_llm": {
"model_name": "gpt-4o",
"api_base": "http://127.0.0.1:8088/v1",
"api_key": "EMPTY",
},
"embeddings": {
"model_name_or_path": "AI-ModelScope/bge-large-zh",
},
"metrics": [
"MultiModalFaithfulness",
"MultiModalRelevance",
],
},
},
}
run_task(task_cfg=multi_modal_task_cfg)
输出结果示例:
[
{
"user_input": "图片中的汽车品牌是什么?",
"retrieved_contexts": ["custom_eval/multimodal/images/tesla.jpg"],
"response": "特斯拉是一个汽车品牌。",
"reference": "图片中的汽车品牌是特斯拉。",
"faithful_rate": true,
"relevance_rate": true
}
]
该场景注意事项#
critic_llm必须使用支持多模态图文交错输入的模型(如gpt-4o)。多模态专用指标为
MultiModalFaithfulness和MultiModalRelevance。不涉及图片的通用指标(如
AnswerCorrectness)同样可用,参考 metrics 列表。embeddings为可选参数,可不指定。
完整参数参考#
通用配置#
task_cfg = {
"eval_backend": "RAGEval", # 固定值
"eval_config": {
"tool": "RAGAS", # 固定值
"eval": { ... }, # 评测配置(场景一/三)
"testset_generation": { ... } # 数据生成配置(场景二)
},
}
eval 参数(RAGASEvalConfig)#
参数 |
类型 |
默认值 |
说明 |
|---|---|---|---|
|
|
- |
评测数据集文件路径 |
|
|
- |
评测 LLM 配置(见 LLM 配置表) |
|
|
- |
嵌入模型配置(见 Embedding 配置表) |
|
|
|
评测指标,参考 metrics 列表 |
|
|
|
语言设置 |
|
|
|
批量大小 |
|
|
|
是否抛出异常 |
testset_generation 参数(RAGASTestsetConfig)#
参数 |
类型 |
默认值 |
说明 |
|---|---|---|---|
|
|
- |
源文档路径列表 |
|
|
|
生成测试集大小 |
|
|
|
输出文件路径 |
|
|
- |
生成器 LLM 配置(见 LLM 配置表) |
|
|
- |
嵌入模型配置(见 Embedding 配置表) |
|
|
|
语言设置 |
generator_llm / critic_llm 参数(RAGASLLMConfig)#
参数 |
类型 |
默认值 |
说明 |
|---|---|---|---|
|
|
- |
模型名称,如 |
|
|
|
提供商 |
|
|
|
API 地址,如 |
|
|
|
API 密钥 |
|
|
|
生成温度 |
|
|
|
最大 token 数 |
embeddings 参数(RAGASEmbeddingConfig)#
参数 |
类型 |
默认值 |
说明 |
|---|---|---|---|
|
|
- |
模型名称或路径,如 |
|
|
|
提供商 |
|
|
|
API 地址(使用 API embedding 时) |
|
|
|
API 密钥 |
常见问题#
LLM 报错 / API 超时#
确保 LLM 服务已正常启动,
api_base地址可访问。若使用本地模型(如 vLLM 部署),确认模型已完成加载。
超时问题可尝试增加客户端超时时间或减少
batch_size。
指标含义详解#
指标 |
评测维度 |
是否需要 reference |
|---|---|---|
|
答案是否忠于上下文(无幻觉) |
否 |
|
答案是否与问题相关 |
否 |
|
上下文中相关信息占比 |
是 |
|
回答所需信息的检索完整度 |
是 |
|
答案与标准答案的一致性 |
是 |
|
多模态答案是否忠于图文上下文 |
否 |
|
多模态答案是否与问题相关 |
否 |
模型选择建议#
评测模型(critic_llm):建议使用 70B+ 参数的指令模型或闭源模型(如 GPT-4o),以确保评分稳定可靠。
生成模型(generator_llm):同样建议 70B+ 参数的模型,小模型容易输出格式错误导致生成失败。
嵌入模型(embeddings):可使用轻量模型如
AI-ModelScope/m3e-base或AI-ModelScope/bge-large-zh。