Qwen3-VL 模型评测最佳实践#
Qwen3-VL 系列——这是迄今为止 Qwen 系列中最强大的视觉语言模型,在多个维度实现了全面跃升:无论是纯文本理解与生成,还是视觉内容的感知与推理;无论是上下文长度的支持能力,还是对空间关系、动态视频的理解深度;乃至在与Agent交互中的表现,Qwen3-VL 都展现出显著进步。在这篇最佳实践中,我们将使用EvalScope框架以Qwen3-VL模型进行全面评测,覆盖模型服务推理性能评测和模型能力评测。
安装依赖#
首先,安装EvalScope模型评估框架:
pip install 'evalscope[app,perf]' -U
模型服务推理性能评测#
首先,对于多模态模型,我们需要通过OpenAI API兼容的推理服务接入模型能力,以进行评测,暂不支持本地使用transformers进行推理。除了将模型部署到支持OpenAI接口的云端服务外,还可以选择在本地使用vLLM、ollama等框架直接启动模型。这些推理框架能够很好地支持并发多个请求,从而加速评测过程。
DashScope API 服务性能评测#
由于模型参数量较大,这里我们使用百炼平台(DashScope)提供的API来访问Qwen3-VL(在平台上对应的模型为 qwen-vl-plus-latest),并对模型服务进行压测。
TIPs: 你也可以使用modelscope提供的免费API进行试用,具体可参考:https://modelscope.cn/docs/model-service/API-Inference/intro
压测命令:
输入:100 tokens文本 + 1张 512*512 图像
输出:128 tokens
evalscope perf \
--model qwen-vl-plus-latest \
--url https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions \
--api-key "API_KEY" \
--parallel 1 2 5 \
--number 4 8 20 \
--api openai \
--dataset random_vl \
--min-tokens 128 \
--max-tokens 128 \
--prefix-length 0 \
--min-prompt-length 100 \
--max-prompt-length 100 \
--image-width 512 \
--image-height 512 \
--image-format RGB \
--image-num 1 \
--tokenizer-path Qwen/Qwen3-VL-235B-A22B-Instruct
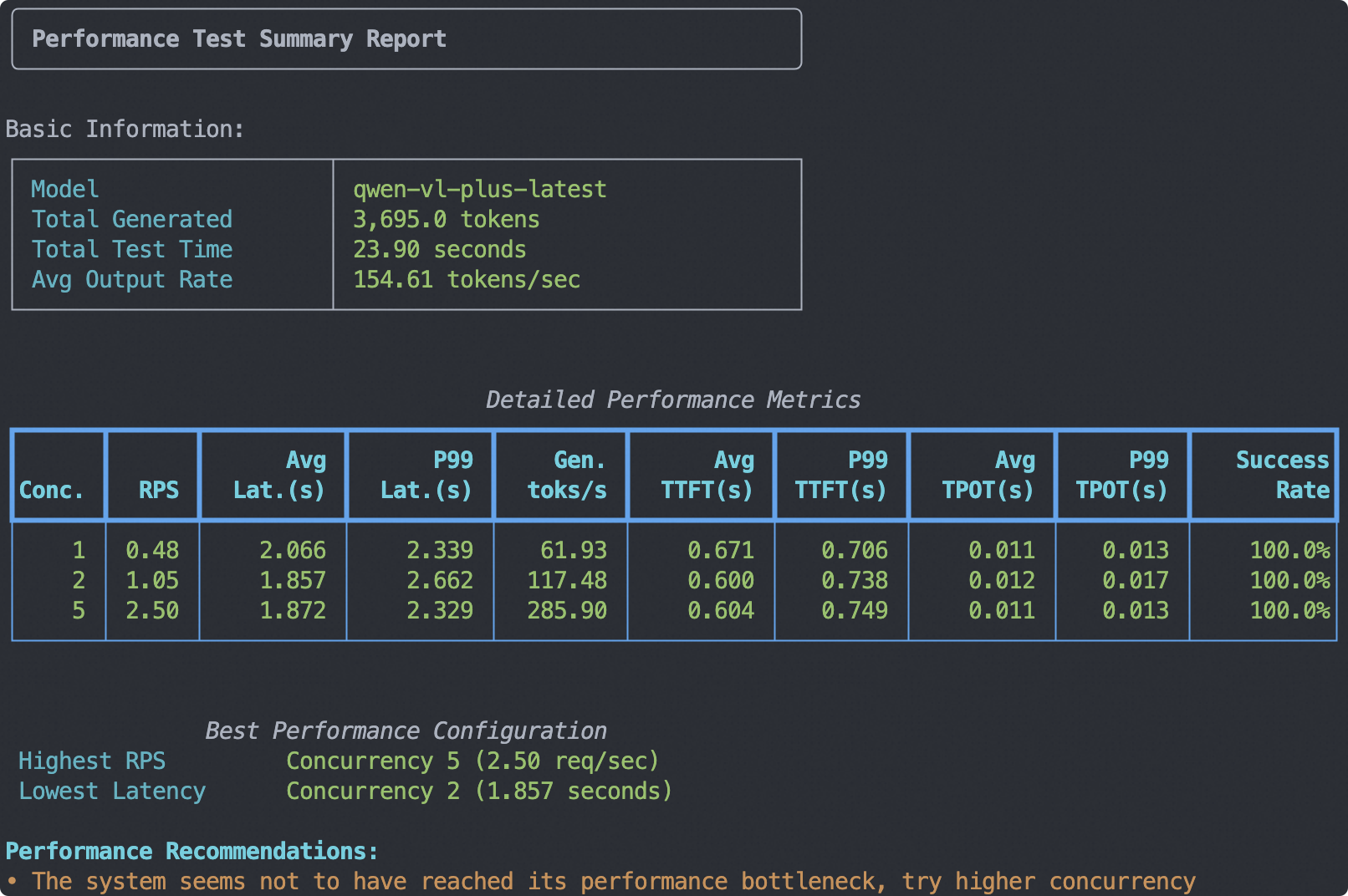
输出报告如下:
模型能力评测#
下面开始进行模型能力评测流程。
注意:后续评测流程都基于API模型服务,你可以根据模型推理框架使用步骤拉起模型服务。
构建评测集合(可选)#
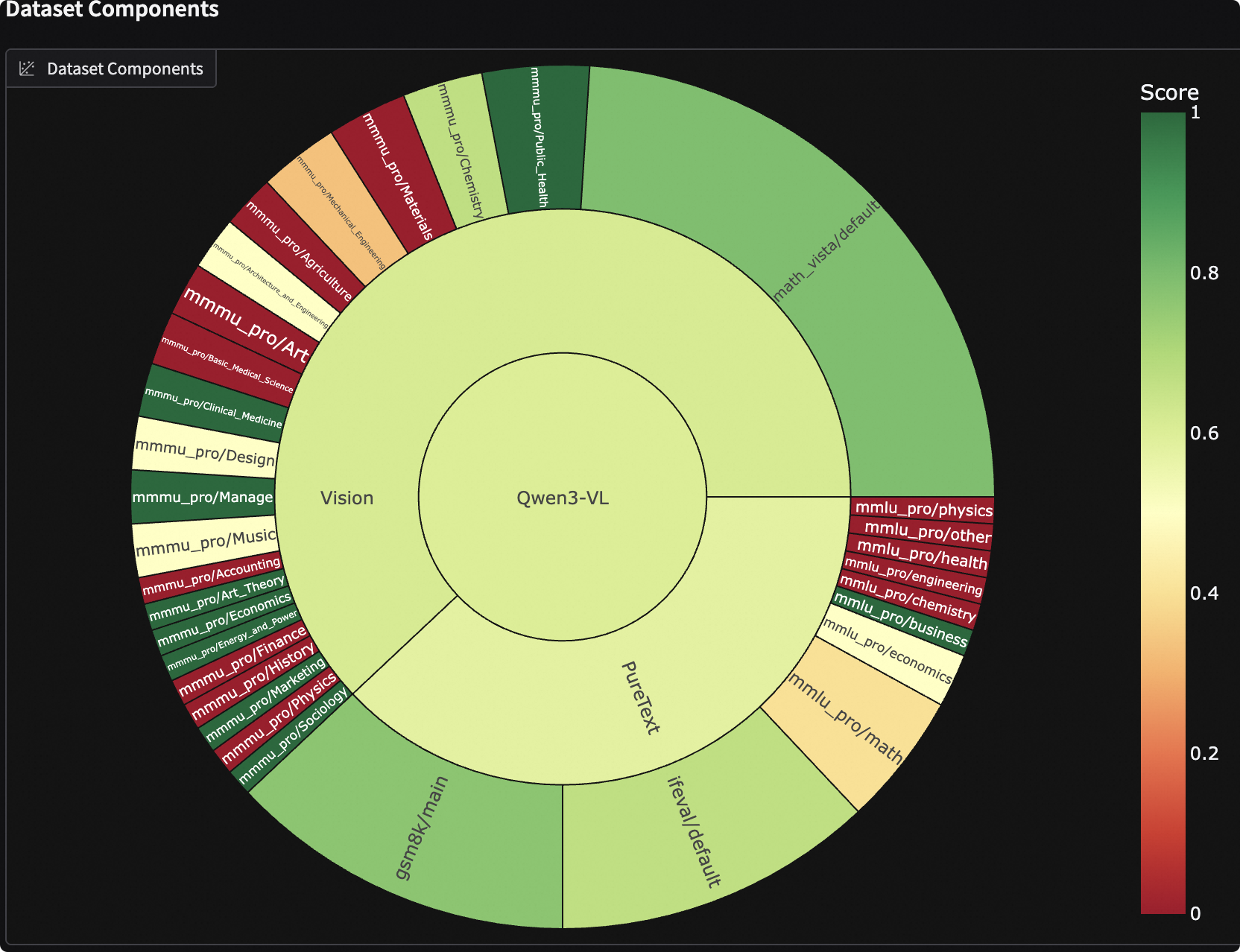
为了全面评测模型的各方面能力,我们可以混合EvalScope已支持的benchmark,构建一个全面的评测集合。下面是一个评测集合的例子,覆盖了主流的benchmark,评测了模型的数学能力(GSM8K)、知识能力(MMLU-Pro)、指令遵循(IFEval)、多模态知识能力(MMMU-Pro)、多模态数学能力(MathVista)等。
运行如下代码即可根据定义的Schema自动下载并混合数据集,并将构建的评测集合保存在本地的jsonl文件中。当然你也可以跳过这个步骤,直接使用我们放在了ModelScope仓库中处理好的数据集合。
from evalscope.collections import CollectionSchema, DatasetInfo, WeightedSampler
from evalscope.utils.io_utils import dump_jsonl_data
schema = CollectionSchema(name='Qwen3-VL', datasets=[
CollectionSchema(name='PureText', weight=1, datasets=[
DatasetInfo(name='mmlu_pro', weight=1, task_type='exam', tags=['en'], args={'few_shot_num': 0}),
DatasetInfo(name='ifeval', weight=1, task_type='instruction', tags=['en'], args={'few_shot_num': 0}),
DatasetInfo(name='gsm8k', weight=1, task_type='math', tags=['en'], args={'few_shot_num': 0}),
]),
CollectionSchema(name='Vision', weight=2, datasets=[
DatasetInfo(name='math_vista', weight=1, task_type='math', tags=['en'], args={'few_shot_num': 0}),
DatasetInfo(name='mmmu_pro', weight=1, task_type='exam', tags=['en'], args={'few_shot_num': 0}),
])
])
# get the mixed data
mixed_data = WeightedSampler(schema).sample(1000)
# dump the mixed data to a jsonl file
dump_jsonl_data(mixed_data, 'outputs/qwen3_vl_test.jsonl')
运行评测任务#
运行如下代码即可评测Qwen3-VL的模型性能:
from dotenv import dotenv_values
env = dotenv_values('.env')
from evalscope import TaskConfig, run_task
from evalscope.constants import EvalType
task_cfg = TaskConfig(
model='qwen-vl-plus-latest',
api_url='https://dashscope.aliyuncs.com/compatible-mode/v1',
api_key=env.get('DASHSCOPE_API_KEY'),
eval_type=EvalType.SERVICE,
datasets=[
'data_collection',
],
dataset_args={
'data_collection': {
'dataset_id': 'evalscope/Qwen3-VL-Test-Collection',
}
},
eval_batch_size=5,
generation_config={
'max_tokens': 30000, # 最大生成token数,建议设置为较大值避免输出截断
'temperature': 0.6, # 采样温度 (qwen 报告推荐值)
'top_p': 0.95, # top-p采样 (qwen 报告推荐值)
'top_k': 20, # top-k采样 (qwen 报告推荐值)
'n': 1, # 每个请求产生的回复数量
},
limit=100, # 设置为100条数据进行测试
)
run_task(task_cfg=task_cfg)
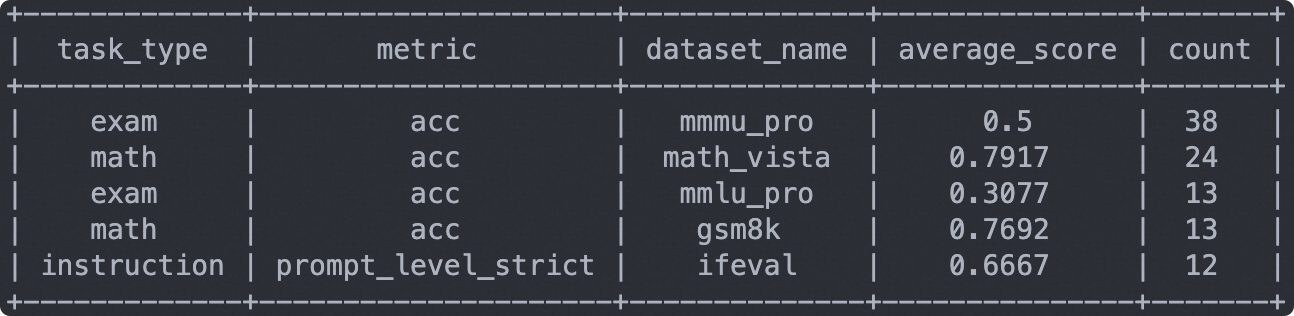
输出结果如下:
注意:下面的结果是取了100条数据的结果,只用于评测流程测试。在正式评测时需要去掉该限制。
评测结果可视化#
EvalScope支持可视化结果,可以查看模型具体的输出。
运行以下命令,可以启动基于Gradio的可视化界面:
evalscope app
选择评测报告,点击加载,即可看到模型在每个问题上的输出结果,以及整体答题正确率: