Qwen3-Next 模型评测最佳实践#
Qwen3-Next 是 Qwen 系列的下一代基础模型,模型在推理、指令跟随、代理能力和多语言支持方面取得了突破性的进展。在这篇最佳实践中,我们将使用EvalScope框架以Qwen3-Next-80B-A3B-Instruct模型为例进行全面评测,覆盖模型服务推理性能评测和模型能力评测。
安装依赖#
首先,安装EvalScope模型评估框架:
pip install 'evalscope[app,perf]' -U
pip install git+https://github.com/huggingface/transformers.git@main
模型服务推理性能评测#
首先,我们需要通过OpenAI API兼容的推理服务接入模型能力,以进行评测。值得注意的是,EvalScope也支持使用transformers进行模型推理评测,详细信息可参考文档。
除了将模型部署到支持OpenAI接口的云端服务外,还可以选择在本地使用vLLM、ollama等框架直接启动模型。这些推理框架能够很好地支持并发多个请求,从而加速评测过程。
下面以vLLM为例,介绍如何在本地启动Qwen3-Next-80B-A3B-Instruct模型服务,并进行性能评测。
安装依赖#
使用vLLM框架(需要nightly版本vLLM和最新版transformers),安装如下依赖:
pip install vllm --pre --extra-index-url https://wheels.vllm.ai/nightly
启动模型服务#
以下命令可用于在 http://localhost:8801/v1 上创建一个 API 端点,最大上下文长度为 8K 个token,并在 4 个 GPU 上使用张量并行:
VLLM_USE_MODELSCOPE=true VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 vllm serve Qwen/Qwen3-Next-80B-A3B-Instruct --served-model-name Qwen3-Next-80B-A3B-Instruct --port 8801 --tensor-parallel-size 4 --max-model-len 8000 --gpu-memory-utilization 0.9 --max-num-seqs 32
备注
目前需要环境变量 VLLM_ALLOW_LONG_MAX_MODEL_LEN=1。
默认上下文长度为 256K。如果服务器无法启动,请考虑将上下文长度减少到较小的值,例如 8000,以及最大序列数减少到32。
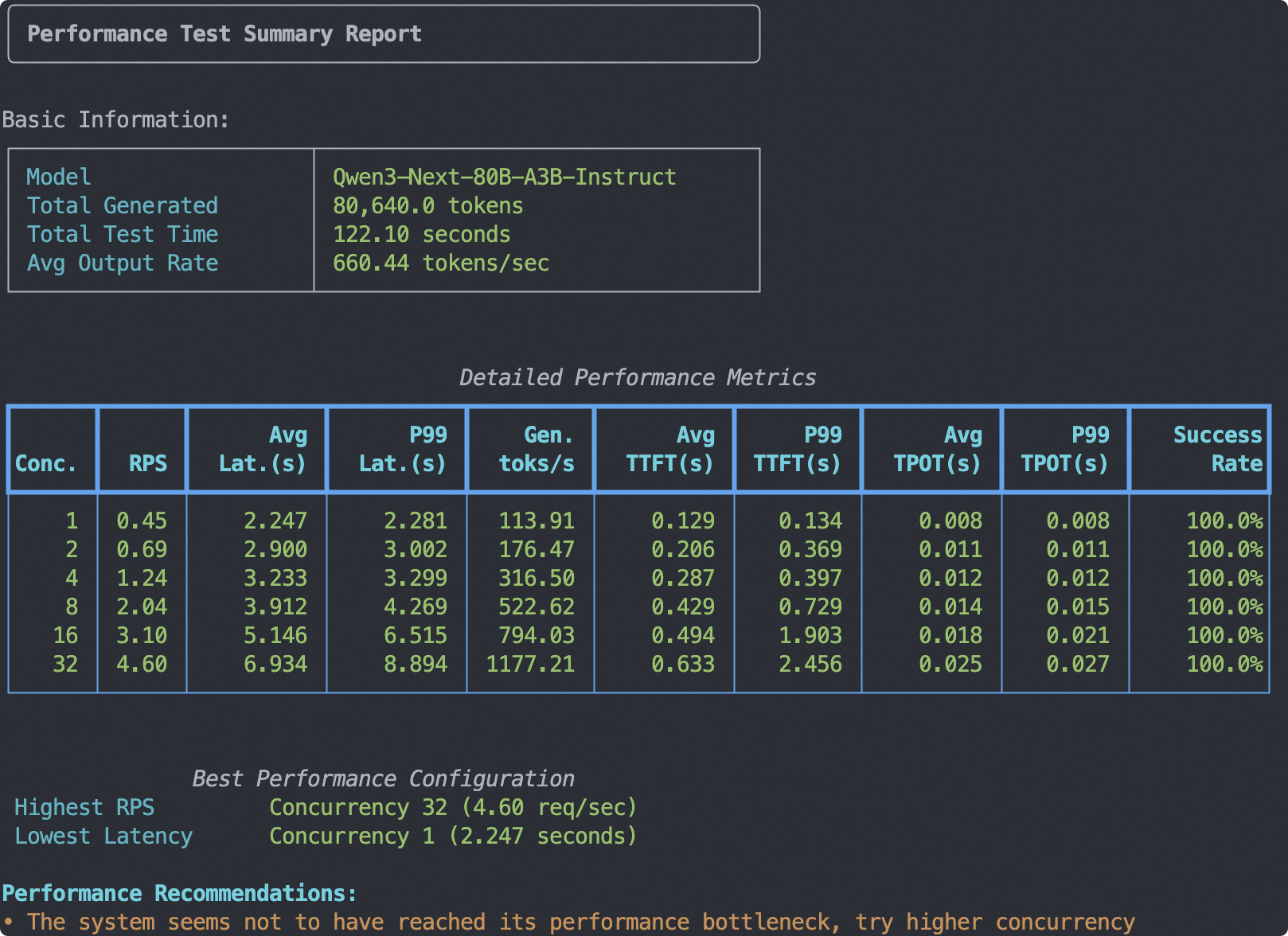
启动压测#
测试环境为4 * A100 80G
测试模型为Qwen3-Next-80B-A3B-Instruct
测试数据为随机生成的1024长度的token
测试输出长度为256的token
测试并发数为1,2,4,8,16,32
运行如下命令:
evalscope perf \
--url "http://127.0.0.1:8801/v1/chat/completions" \
--parallel 1 2 4 8 16 32 \
--number 5 10 20 40 80 160 \
--model Qwen3-Next-80B-A3B-Instruct \
--api openai \
--dataset random \
--min-prompt-length 1024 \
--max-prompt-length 1024 \
--min-tokens 256 \
--max-tokens 256 \
--tokenizer-path Qwen/Qwen3-Next-80B-A3B-Instruct \
--extra-args '{"ignore_eos": true}'
参数说明具体可参考性能评测
输出示例如下:
模型能力评测#
下面开始进行模型能力评测流程。
注意:后续评测流程都基于vLLM拉起的模型服务,你可以根据上一步模型服务性能评测的步骤拉起模型服务,或使用本地模型服务。模型默认使用思考模式。
构建评测集合(可选)#
为了全面评测模型的各方面能力,我们可以混合EvalScope已支持的benchmark,构建一个全面的评测集合。下面是一个评测集合的例子,覆盖了主流的benchmark,评测了模型的代码能力(LiveCodeBench)、数学能力(AIME2024, AIME2025)、知识能力(MMLU-Pro, CEVAL)、指令遵循(IFEval)等。
运行如下代码即可根据定义的Schema自动下载并混合数据集,并将构建的评测集合保存在本地的jsonl文件中。当然你也可以跳过这个步骤,直接使用我们放在了ModelScope仓库中处理好的数据集合。
from evalscope.collections import CollectionSchema, DatasetInfo, WeightedSampler
from evalscope.utils.io_utils import dump_jsonl_data
schema = CollectionSchema(name='Qwen3', datasets=[
CollectionSchema(name='English', datasets=[
DatasetInfo(name='mmlu_pro', weight=1, task_type='exam', tags=['en'], args={'few_shot_num': 0}),
DatasetInfo(name='mmlu_redux', weight=1, task_type='exam', tags=['en'], args={'few_shot_num': 0}),
DatasetInfo(name='ifeval', weight=1, task_type='instruction', tags=['en'], args={'few_shot_num': 0}),
]),
CollectionSchema(name='Chinese', datasets=[
DatasetInfo(name='ceval', weight=1, task_type='exam', tags=['zh'], args={'few_shot_num': 0}),
DatasetInfo(name='iquiz', weight=1, task_type='exam', tags=['zh'], args={'few_shot_num': 0}),
]),
CollectionSchema(name='Code', datasets=[
DatasetInfo(name='live_code_bench', weight=1, task_type='code', tags=['en'], args={'few_shot_num': 0, 'subset_list': ['v5_v6'], 'extra_params': {'start_date': '2025-01-01', 'end_date': '2025-04-30'}}),
]),
CollectionSchema(name='Math&Science', datasets=[
DatasetInfo(name='math_500', weight=1, task_type='math', tags=['en'], args={'few_shot_num': 0}),
DatasetInfo(name='aime24', weight=1, task_type='math', tags=['en'], args={'few_shot_num': 0}),
DatasetInfo(name='aime25', weight=1, task_type='math', tags=['en'], args={'few_shot_num': 0}),
DatasetInfo(name='gpqa_diamond', weight=1, task_type='knowledge', tags=['en'], args={'few_shot_num': 0})
])
])
# get the mixed data
mixed_data = WeightedSampler(schema).sample(100000000) # set a large number to ensure all datasets are sampled
# dump the mixed data to a jsonl file
dump_jsonl_data(mixed_data, 'outputs/qwen3_test.jsonl')
运行评测任务#
运行如下代码即可评测Qwen3-Next的模型性能:
from evalscope import TaskConfig, run_task
task_cfg = TaskConfig(
model='Qwen3-Next-80B-A3B-Instruct',
api_url='http://127.0.0.1:8801/v1/chat/completions',
eval_type='openai_api',
datasets=[
'data_collection',
],
dataset_args={
'data_collection': {
'dataset_id': 'evalscope/Qwen3-Test-Collection',
'shuffle': True,
}
},
eval_batch_size=32,
generation_config={
'max_tokens': 6000, # 最大生成token数,建议设置为较大值避免输出截断
'temperature': 0.7, # 采样温度 (qwen 报告推荐值)
'top_p': 0.8, # top-p采样 (qwen 报告推荐值)
'top_k': 20, # top-k采样 (qwen 报告推荐值)
},
timeout=60000, # 超时时间
stream=True, # 是否使用流式输出
limit=100, # 设置为100条数据进行测试
)
run_task(task_cfg=task_cfg)
输出结果如下:
注意 ⚠️:下面的结果是取了100条数据的结果,只用于评测流程测试。在正式评测时需要去掉该限制。
+-------------+---------------------+--------------+---------------+-------+
| task_type | metric | dataset_name | average_score | count |
+-------------+---------------------+--------------+---------------+-------+
| exam | acc | mmlu_pro | 0.7869 | 61 |
| exam | acc | mmlu_redux | 0.913 | 23 |
| exam | acc | ceval | 0.8333 | 6 |
| instruction | prompt_level_strict | ifeval | 0.6 | 5 |
| math | acc | math_500 | 1.0 | 4 |
| knowledge | acc | gpqa_diamond | 0.0 | 1 |
+-------------+---------------------+--------------+---------------+-------+
更多可用的评测数据集可参考数据集列表。
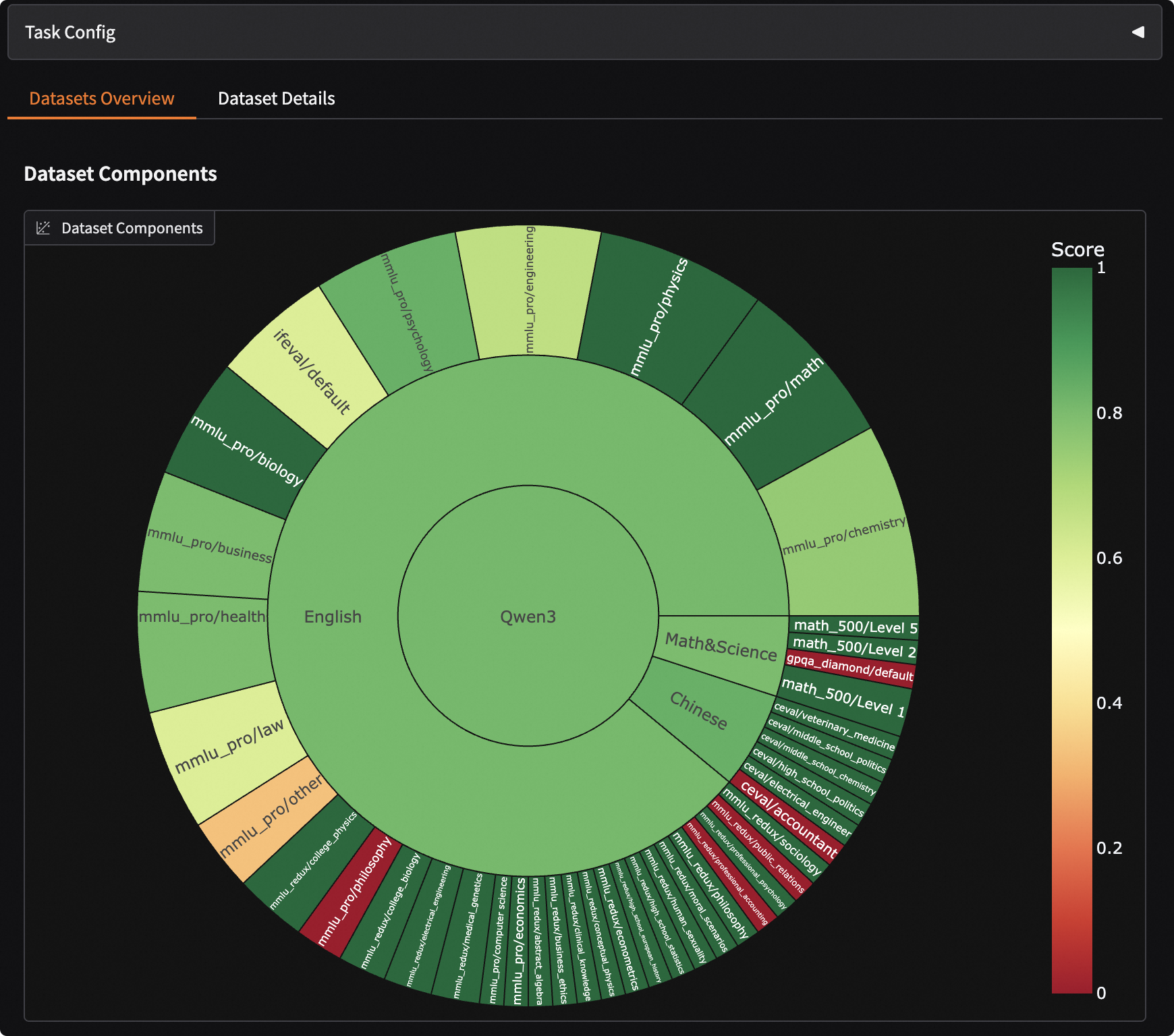
评测结果可视化#
EvalScope支持可视化结果,可以查看模型具体的输出。
运行以下命令,可以启动基于Gradio的可视化界面:
evalscope app
选择评测报告,点击加载,即可看到模型在每个问题上的输出结果,以及整体答题正确率: