快速开始#
下面是使用EvalScope进行模型推理性能压测的快速指南。支持OpenAI API格式模型服务以及多种数据集格式,方便用户进行性能评测。
环境准备#
EvalScope支持在Python环境中使用,用户可以通过pip安装或源码安装EvalScope。以下是两种安装方式的示例:
# 安装额外依赖
pip install evalscope[perf] -U
git clone https://github.com/modelscope/evalscope.git
cd evalscope
pip install -e '.[perf]'
基本使用#
可以使用以下两种方式(命令行/Python脚本)启动模型推理性能压测工具:
下面展示了用vLLM框架在A100上进行Qwen2.5-0.5B-Instruct模型的压测示例,固定输入1024 token,输出1024 token。用户可以根据自己的需求修改参数。
evalscope perf \
--parallel 1 10 50 100 200 \
--number 10 20 100 200 400 \
--model Qwen2.5-0.5B-Instruct \
--url http://127.0.0.1:8801/v1/chat/completions \
--api openai \
--dataset random \
--max-tokens 1024 \
--min-tokens 1024 \
--prefix-length 0 \
--min-prompt-length 1024 \
--max-prompt-length 1024 \
--tokenizer-path Qwen/Qwen2.5-0.5B-Instruct \
--extra-args '{"ignore_eos": true}'
from evalscope.perf.main import run_perf_benchmark
from evalscope.perf.arguments import Arguments
task_cfg = Arguments(
parallel=[1, 10, 50, 100, 200],
number=[10, 20, 100, 200, 400],
model='Qwen2.5-0.5B-Instruct',
url='http://127.0.0.1:8801/v1/chat/completions',
api='openai',
dataset='random',
min_tokens=1024,
max_tokens=1024,
prefix_length=0,
min_prompt_length=1024,
max_prompt_length=1024,
tokenizer_path='Qwen/Qwen2.5-0.5B-Instruct',
extra_args={'ignore_eos': True}
)
results = run_perf_benchmark(task_cfg)
参数说明:
parallel: 请求的并发数,可以传入多个值,用空格隔开number: 发出的请求的总数量,可以传入多个值,用空格隔开(与parallel一一对应)url: 请求的URL地址model: 使用的模型名称api: 使用的API服务,默认为openaidataset: 数据集名称,此处为random,表示随机生成数据集,具体使用说明参考;更多可用的(多模态)数据集请参考数据集配置tokenizer-path: 模型的tokenizer路径,用于计算token数量(在random数据集中是必须的)extra-args: 请求中的额外的参数,传入json格式的字符串,例如{"ignore_eos": true}表示忽略结束token
参见
输出结果#
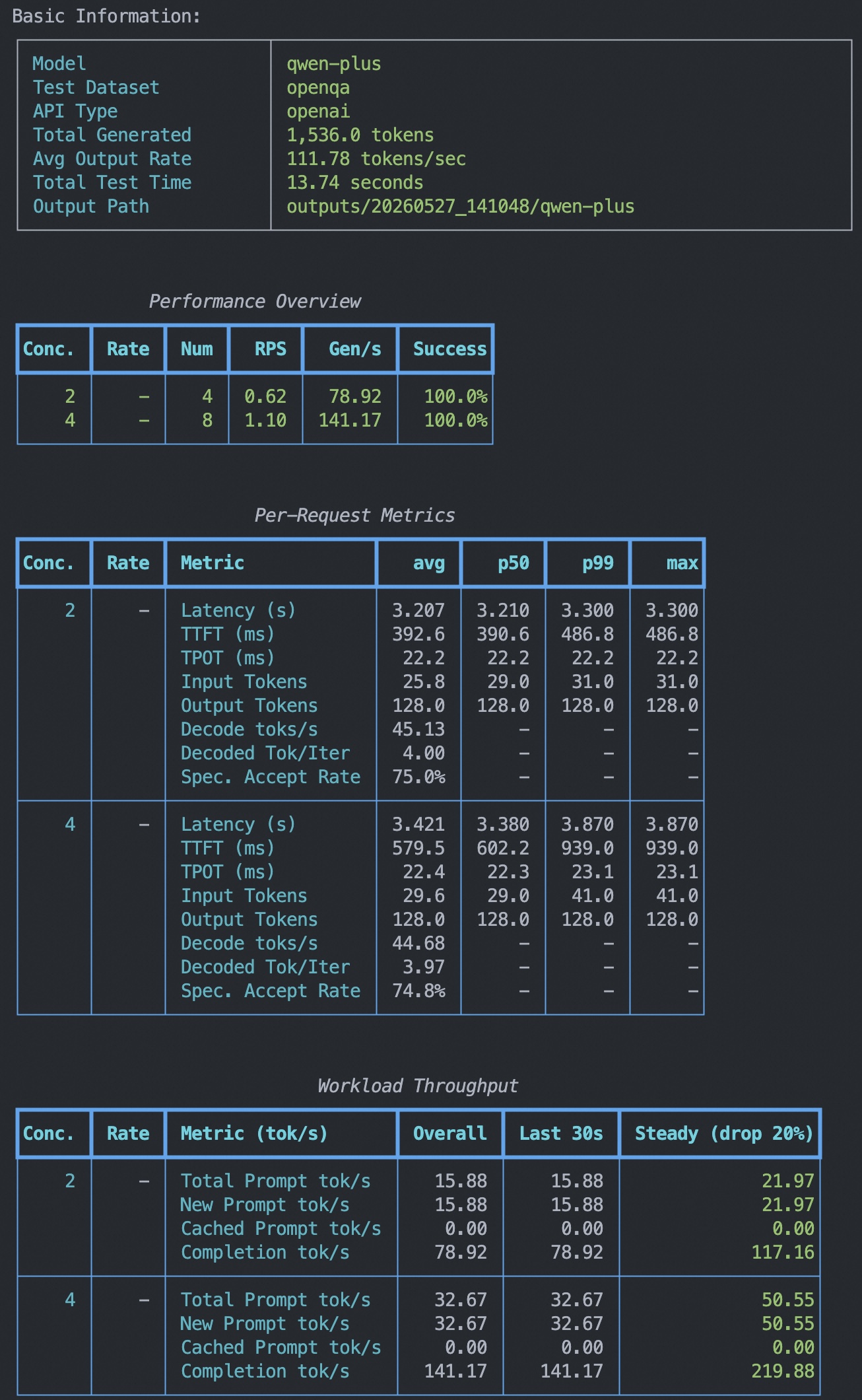
输出的测试报告总结包括基础信息(模型、数据集、API类型等)以及以下四张表:
Performance Overview:每个并发配置一行,展示 RPS、输出吞吐量、成功率等标量指标
Per-Request Metrics:每个配置的延迟、TTFT、TPOT、输入/输出 token 数等分布指标(avg / p50 / p99)
Per-Trace Metrics:多轮对话模式下的对话级指标(仅多轮模式输出)
Workload Throughput:全局时间维度的 token 吞吐率(Overall / Last 30s / Steady)
备注
以上汇总报告针对多个并发数的压测结果,方便用户对比不同并发数下的模型性能表现。单个并发数不会生成该汇总报告。
该报告会保存在
outputs/<timestamp>/<model>/performance_summary.txt中,用户可以根据需要查看。下表中的各项指标解释请参考后续的”指标说明”部分,结果会保存在
outputs/<timestamp>/<model>/benchmark.log。
此外,每个并发数的测试结果会单独输出,包含了每个并发数下的请求数量、成功请求数量、失败请求数量、平均延迟时间、平均每token延迟时间等指标。
Benchmarking summary:
┌───────────────────────────┬───────────────┐
│ Metric │ Value │
├───────────────────────────┼───────────────┤
│ ── General ── │ │
│ Test Duration (s) │ 38.31 │
│ Concurrency │ 200 │
│ Request Rate (req/s) │ -1.00 │
│ Total / Success / Failed │ 400 / 400 / 0 │
│ Req Throughput (req/s) │ 10.44 │
│ ── Latency ── │ │
│ Avg Latency (s) │ 18.78 │
│ TTFT (ms) │ 717.63 │
│ TPOT (ms) │ 17.66 │
│ ITL (ms) │ 17.64 │
│ ── Tokens ── │ │
│ Avg Input Tokens │ 1024.00 │
│ Avg Output Tokens │ 1024.00 │
│ Output Throughput (tok/s) │ 10692.45 │
│ Total Throughput (tok/s) │ 21384.91 │
└───────────────────────────┴───────────────┘
Percentile results:
┌────────────────┬─────────┬─────────┬─────────┬─────────┬─────────┬─────────┬─────────┬─────────┬─────────┐
│ Metric │ 1% │ 5% │ 10% │ 25% │ 50% │ 75% │ 90% │ 95% │ 99% │
├────────────────┼─────────┼─────────┼─────────┼─────────┼─────────┼─────────┼─────────┼─────────┼─────────┤
│ Latency (s) │ 17.25 │ 17.46 │ 17.74 │ 18.14 │ 18.71 │ 19.23 │ 20.28 │ 20.62 │ 20.84 │
│ TTFT (ms) │ 176.30 │ 212.60 │ 246.76 │ 279.87 │ 333.79 │ 1082.24 │ 1812.13 │ 2097.23 │ 2319.52 │
│ ITL (ms) │ 0.00 │ 0.01 │ 0.01 │ 10.62 │ 15.67 │ 20.37 │ 26.97 │ 32.50 │ 50.11 │
│ TPOT (ms) │ 16.61 │ 16.80 │ 17.02 │ 17.31 │ 17.76 │ 18.06 │ 18.18 │ 18.28 │ 18.36 │
│ Input tokens │ 1024.00 │ 1024.00 │ 1024.00 │ 1024.00 │ 1024.00 │ 1024.00 │ 1024.00 │ 1024.00 │ 1024.00 │
│ Output tokens │ 1024.00 │ 1024.00 │ 1024.00 │ 1024.00 │ 1024.00 │ 1024.00 │ 1024.00 │ 1024.00 │ 1024.00 │
│ Output (tok/s) │ 49.15 │ 49.75 │ 50.55 │ 53.33 │ 54.79 │ 56.48 │ 57.73 │ 58.73 │ 59.45 │
│ Total (tok/s) │ 98.30 │ 99.50 │ 101.09 │ 106.66 │ 109.58 │ 112.97 │ 115.46 │ 117.45 │ 118.89 │
│ Decode (tok/s) │ 54.46 │ 54.74 │ 55.07 │ 55.38 │ 56.31 │ 57.80 │ 58.77 │ 59.55 │ 60.24 │
└────────────────┴─────────┴─────────┴─────────┴─────────┴─────────┴─────────┴─────────┴─────────┴─────────┘
指标说明#
基础指标#
指标 |
英文名称 |
解释 |
公式 |
|---|---|---|---|
测试总时长 |
Test Duration (s) |
整个测试过程从开始到结束所花费的总时间 |
最后一个请求结束时间 - 第一个请求开始时间 |
并发数 |
Concurrency |
同时发送请求的客户端数量 |
预设值 |
请求速率 |
Request Rate (req/s) |
目标请求调度速率;-1 表示不做速率节流,默认 closed-loop 模式下仍受 |
预设值 |
总请求数 / 成功数 / 失败数 |
Total / Success / Failed |
在整个测试过程中发送的所有请求数量及其成功与失败数 |
成功请求数 + 失败请求数 |
请求吞吐量 |
Req Throughput (req/s) |
每秒钟成功处理的平均请求数 |
成功请求数 / 测试总时长 |
平均延迟 |
Avg Latency (s) |
从发送请求到接收完整响应的平均时间 |
总延迟时间 / 成功请求数 |
平均首token时间 |
TTFT (ms) |
从发送请求到接收到第一个响应标记的平均时间 |
总首chunk延迟 / 成功请求数 |
平均每输出token时间 |
TPOT (ms) |
生成每个输出标记所需的平均时间(不包含首token) |
总每输出token时间 / 成功请求数 |
平均输出token间时延 |
ITL (ms) |
生成每个输出token之间的平均间隔时间 |
总输出token间时延 / 成功请求数 |
平均输入token数 |
Avg Input Tokens |
每个请求的平均输入标记数 |
总输入token数 / 成功请求数 |
平均输出token数 |
Avg Output Tokens |
每个请求的平均输出标记数 |
总输出token数 / 成功请求数 |
输出吞吐量 |
Output Throughput (tok/s) |
每秒钟输出的平均token数 |
总输出token数 / 测试总时长 |
总吞吐量 |
Total Throughput (tok/s) |
每秒钟处理的平均token数(输入+输出) |
(总输入token数 + 总输出token数) / 测试总时长 |
解码速率 |
Decode toks/s |
每秒解码输出的token数(不含首token) |
1000 / TPOT |
多轮对话指标#
以下指标仅在多轮对话模式下输出,详细说明请参考多轮对话压测。
指标 |
英文名称 |
解释 |
公式 |
|---|---|---|---|
平均输入轮数 |
Turns/Req |
多轮对话中每个请求的平均历史对话轮数(单轮时为1) |
总输入轮数 / 成功请求数 |
近似KV缓存命中率 |
Cache Hit (%) |
基于cached token占输入token比例估算的前缀缓存命中率(需服务端开启prefix caching并返回cached_tokens字段) |
总cached token数 / 总输入token数 × 100% |
首轮首token延迟 |
1st-Turn TTFT (ms) |
多轮对话中首轮(冷prefill)的平均首token延迟 |
所有首轮TTFT之和 / 对话数 |
后续轮首token延迟 |
Subseq. TTFT (ms) |
多轮对话中后续轮(可命中prefix cache)的平均首token延迟 |
所有后续轮TTFT之和 / 后续轮请求数 |
投机解码指标#
以下指标仅在投机解码场景下输出。
指标 |
英文名称 |
解释 |
公式 |
|---|---|---|---|
平均每次解码输出token数 |
Decoded Tok/Iter |
每次大模型前向推理(iteration)平均接受的token数,反映draft model的命中效果 |
(总输出token数 - 1) / (总chunk数 - 1) |
近似投机解码接受率 |
Spec. Accept Rate |
投机解码的近似token接受率,由每次解码输出token数推导,越接近1表示draft model越准确 |
1 - 1 / (平均每次解码输出token数) |
百分位指标 (Percentile)#
以单个请求为单位进行统计,数据被分为100个相等部分,第n百分位表示n%的数据点在此值之下。
指标 |
英文名称 |
解释 |
|---|---|---|
端到端延迟时间 |
Latency (s) |
从发送请求到接收完整响应的时间(以秒为单位):TTFT + TPOT * Output tokens |
首次生成token时间 |
TTFT (ms) |
从发送请求到生成第一个token的时间(以毫秒为单位),评估首包延时 |
输出token间时延 |
ITL (ms) |
生成每个输出token间隔时间(以毫秒为单位),评估输出是否平稳 |
每token延迟 |
TPOT (ms) |
生成每个输出token所需的时间(不包含首token,以毫秒为单位),评估解码速度 |
输入token数 |
Input tokens |
请求中输入的token数量 |
输出token数 |
Output tokens |
响应中生成的token数量 |
输出吞吐量 |
Output (tok/s) |
每秒输出的token数量:输出tokens / 端到端延时 |
总吞吐量 |
Total (tok/s) |
每秒处理的token数量:(输入tokens + 输出tokens) / 端到端延时 |
解码吞吐量 |
Decode (tok/s) |
每秒解码输出的token数量 |
Per-Trace 与 Workload Throughput 指标#
多轮对话模式下还会输出 Per-Trace Metrics(对话级分布指标)和 Workload Throughput(全局时间维度token吞吐率)两张表,详细说明请参考多轮对话压测 — 多轮专属输出指标。
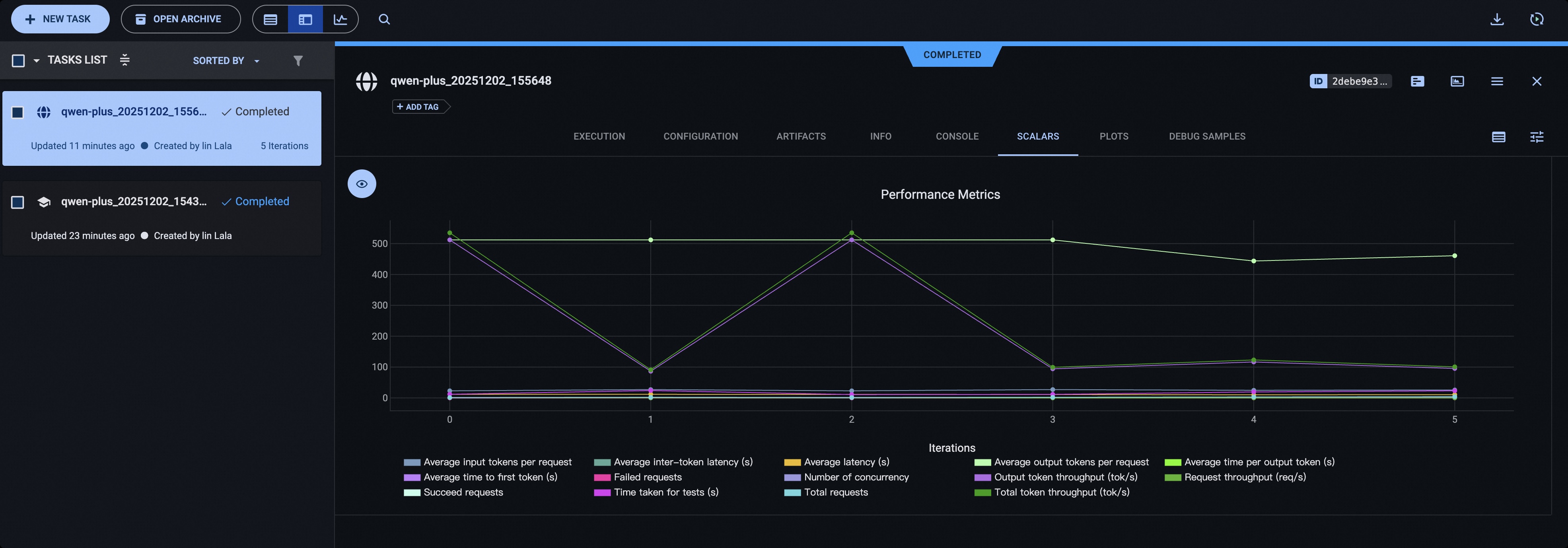
可视化测试结果#
使用Wandb#
请先安装wandb,并获取对应的API Key:
pip install wandb
在评测启动时,额外添加以下参数,即可将测试结果上传wandb server并进行可视化:
# ...
--visualizer wandb
--name 'name_of_wandb_log'
例如:

使用SwanLab#
请先安装SwanLab,并获取对应的API Key
pip install swanlab
在评测启动时,额外添加以下参数,即可将测试结果上传swanlab server并进行可视化:
# ...
--visualizer swanlab
--name 'name_of_swanlab_log'
例如:

如果希望仅使用SwanLab本地看板模式,先安装swanlab离线看板:
pip install 'swanlab[dashboard]'
再通过设置如下参数:
--swanlab-api-key local
并通过swanlab watch <日志路径>打开本地可视化看板。
使用ClearML#
请使用如下命令安装ClearML:
pip install clearml
初始化ClearML服务器:
clearml-init
启动测试前添加如下参数:
# 可使用 CLEARML_PROJECT_NAME 环境变量指定项目名称
--visualizer clearml
--name 'name_of_clearml_task'