你家的AI有多聪明?智商和情商全评测!#
在人工智能的浪潮中,各式各样的模型如雨后春笋般涌现,其中不乏像OpenAI最新发布的GPT-4.5这样备受关注的高情商模型。它们在各类榜单中占据着显赫的位置,令人眼花缭乱。然而,这些模型获得的分数究竟是如何测出来的?每当我们在榜单上看到那些令人印象深刻的分数时,你是否也曾好奇过背后的评测奥秘?在这个教程中,我们将带你揭秘这一切,手把手教你评测模型的智商和情商。
我们将使用EvalScope模型评测框架,在IQuiz数据集上进行评测,这个数据集中我们收集了40道IQ测试和80道EQ测试选择题,其中包括一些经典问题:
数字9.8和9.11哪个大?
单词 strawberry 和 blueberry 中一共有多少个 r ?
刘雨正在休假,突然被要求开车送领导去机场,他正为休假计划的泡汤而懊恼,因此在送领导时,刹车踩得比较用力。在车上,领导突然说:“小刘啊,这不愧是有着悠久历史的西安,我这坐车有一种回到古代坐马车的感觉。” 领导是什么意思?
可以点击这里看看你能答对多少,再期待一下AI模型的表现吧。
本教程包括以下内容:
备注
本教程可以直接在ModelScope的免费Notebook环境中运行,请点击这里
安装 EvalScope#
pip install 'evalscope[service]' -U
评测本地模型checkpoint#
运行下面的命令将自动从modelscope下载对应模型,并使用IQuiz数据集进行评测,根据模型输出结果和标准答案对模型进行评分,评测结果将保存在当前目录下的outputs文件夹中。
命令参数包含如下内容:
model:被评测的模型名称。
datasets:数据集名称,支持输入多个数据集,使用空格分开。
更多支持的参数请参考:https://evalscope.readthedocs.io/zh-cn/latest/get_started/parameters.html
评测Qwen2.5-0.5B-Instruct#
这个是通义千问官方的Qwen2.5系列0.5B大小的模型,模型链接 https://modelscope.cn/models/Qwen/Qwen2.5-0.5B-Instruct
推理时大约占用2.6G显存
CUDA_VISIBLE_DEVICES=0 \
evalscope eval \
--model Qwen/Qwen2.5-0.5B-Instruct \
--datasets iquiz
输出评测报告示例如下:
+-----------------------+-----------+-----------------+----------+-------+---------+---------+
| Model | Dataset | Metric | Subset | Num | Score | Cat.0 |
+=======================+===========+=================+==========+=======+=========+=========+
| Qwen2.5-0.5B-Instruct | iquiz | AverageAccuracy | IQ | 40 | 0.05 | default |
+-----------------------+-----------+-----------------+----------+-------+---------+---------+
| Qwen2.5-0.5B-Instruct | iquiz | AverageAccuracy | EQ | 80 | 0.1625 | default |
+-----------------------+-----------+-----------------+----------+-------+---------+---------+
评测Qwen2.5-7B-Instruct#
这个是通义千问官方的Qwen2.5系列70亿参数大小的模型,模型链接 https://modelscope.cn/models/Qwen/Qwen2.5-7B-Instruct
推理时大约占用16G显存
让我们来看看参数量更大的模型是否有更好的表现
CUDA_VISIBLE_DEVICES=0 \
evalscope eval \
--model Qwen/Qwen2.5-7B-Instruct \
--datasets iquiz
输出评测报告示例如下:
+---------------------+-----------+-----------------+----------+-------+---------+---------+
| Model | Dataset | Metric | Subset | Num | Score | Cat.0 |
+=====================+===========+=================+==========+=======+=========+=========+
| Qwen2.5-7B-Instruct | iquiz | AverageAccuracy | IQ | 40 | 0.6 | default |
+---------------------+-----------+-----------------+----------+-------+---------+---------+
| Qwen2.5-7B-Instruct | iquiz | AverageAccuracy | EQ | 80 | 0.6625 | default |
+---------------------+-----------+-----------------+----------+-------+---------+---------+
从初步评测结果可以看出7B大小的模型在IQ和EQ上都远超0.5B大小的模型。
评测API模型服务#
EvalScope还支持API评测,下面我们使用API评测Qwen2.5-72B-Instruct-GPTQ-Int4模型。
首先使用vLLM启动Qwen2.5-72B-Instruct-GPTQ-Int4模型,并使用API评测。
VLLM_USE_MODELSCOPE=True CUDA_VISIBLE_DEVICES=0 python -m vllm.entrypoints.openai.api_server --model Qwen/Qwen2.5-72B-Instruct-GPTQ-Int4 --gpu-memory-utilization 0.9 --served-model-name Qwen2.5-72B-Instruct --trust_remote_code --port 8801
使用EvalScope评测API评测:
evalscope eval \
--model Qwen2.5-72B-Instruct \
--api-url http://localhost:8801/v1 \
--api-key EMPTY \
--eval-type openai_api \
--eval-batch-size 16 \
--datasets iquiz
输出评测报告示例如下:
+----------------------+-----------+-----------------+----------+-------+---------+---------+
| Model | Dataset | Metric | Subset | Num | Score | Cat.0 |
+======================+===========+=================+==========+=======+=========+=========+
| Qwen2.5-72B-Instruct | iquiz | AverageAccuracy | IQ | 40 | 0.825 | default |
+----------------------+-----------+-----------------+----------+-------+---------+---------+
| Qwen2.5-72B-Instruct | iquiz | AverageAccuracy | EQ | 80 | 0.8125 | default |
+----------------------+-----------+-----------------+----------+-------+---------+---------+
从评测结果可以看出,72B大小的模型在IQ和EQ上都远超0.5B和7B大小的模型。
可视化模型评测结果#
下面我们启动EvalScope的可视化界面,来具体看看模型对每个问题是如何回答的
evalscope service
点击链接即可看到如下可视化界面,我们需要先选择评测报告然后点击加载:
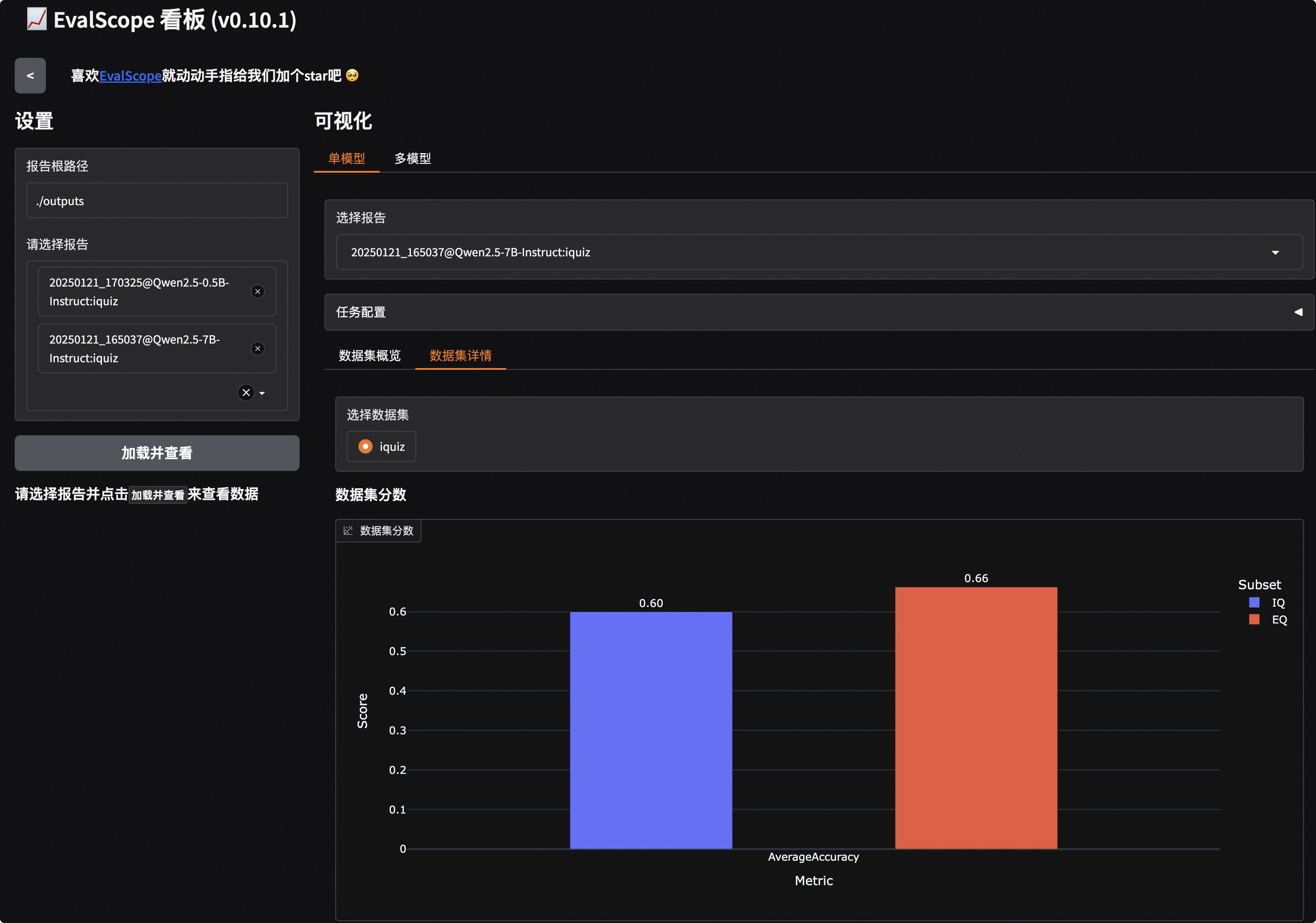
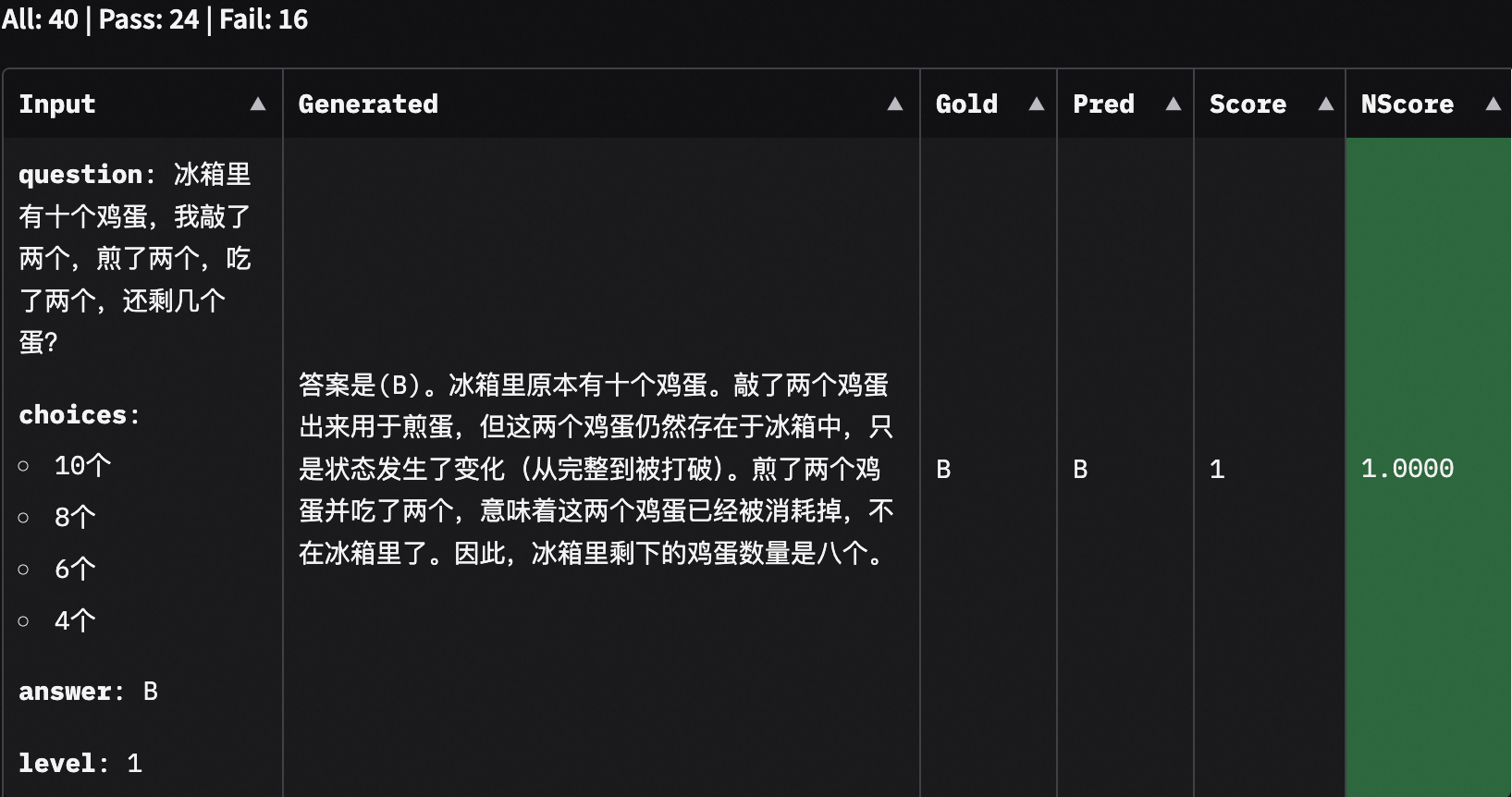
此外,选择对应的子数据集,我们也可以查看模型的输出内容:
总结#
从模型输出结果看0.5B的模型倾向于直接输出选项,并且没有按要求给出解释;7B大小的模型基本都能给出让人信服的解释。从这个评测结果来看,下次如果你希望让AI来帮你写作业,记得用参数量更大的模型,或者用本教程的工具来测一测。如果你还没尽兴的话,可以阅读Evalscope的使用指南,使用更多的数据集来评测你自己训练的模型!