Qwen3-Omni 模型评测最佳实践#
Qwen3-Omni是新一代原生全模态大模型,能够无缝处理文本、图像、音频和视频等多种输入形式,并通过实时流式响应同时生成文本与自然语音输出。在这篇最佳实践中,我们将使用EvalScope框架以Qwen3-Omni-30B-A3B-Instruct模型为例进行评测,覆盖模型服务推理性能评测和模型能力评测。
安装依赖#
首先,安装EvalScope模型评估框架:
pip install 'evalscope[app,perf]' -U
模型服务推理性能评测#
首先,对于多模态模型,我们需要通过OpenAI API兼容的推理服务接入模型能力,以进行评测,暂不支持本地使用transformers进行推理。你可以将模型部署到支持OpenAI API接口的云端服务,还可以选择在本地使用vLLM、ollama等框架直接启动模型。这些推理框架能够很好地支持并发多个请求,从而加速评测过程。
下面以vLLM为例,介绍如何在本地启动Qwen3-Omni-30B-A3B-Instruct模型服务,并进行性能评测。
安装依赖#
由于提交到vLLM的代码目前(2025.9.25)处于拉取请求阶段,并且 instruction 模型的音频输出推理支持将在不久的将来发布,您可以按照以下命令从源码安装 vLLM。请注意,我们建议您创建一个新的 Python 环境以避免运行时环境冲突和不兼容:
git clone -b qwen3_omni https://github.com/wangxiongts/vllm.git
cd vllm
pip install -r requirements/build.txt
pip install -r requirements/cuda.txt
export VLLM_PRECOMPILED_WHEEL_LOCATION=https://wheels.vllm.ai/a5dd03c1ebc5e4f56f3c9d3dc0436e9c582c978f/vllm-0.9.2-cp38-abi3-manylinux1_x86_64.whl
VLLM_USE_PRECOMPILED=1 pip install -e . -v --no-build-isolation
# If you meet an "Undefined symbol" error while using VLLM_USE_PRECOMPILED=1, please use "pip install -e . -v" to build from source.
# Install the Transformers
pip install git+https://github.com/huggingface/transformers
pip install accelerate
pip install qwen-omni-utils -U
pip install -U flash-attn --no-build-isolation
启动模型服务#
以下命令可用于在 http://localhost:8801/v1 上创建一个 API 端点:
VLLM_USE_MODELSCOPE=true vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct --port 8801 --dtype bfloat16 --max-model-len 32768 --served-model-name Qwen3-Omni-30B-A3B-Instruct
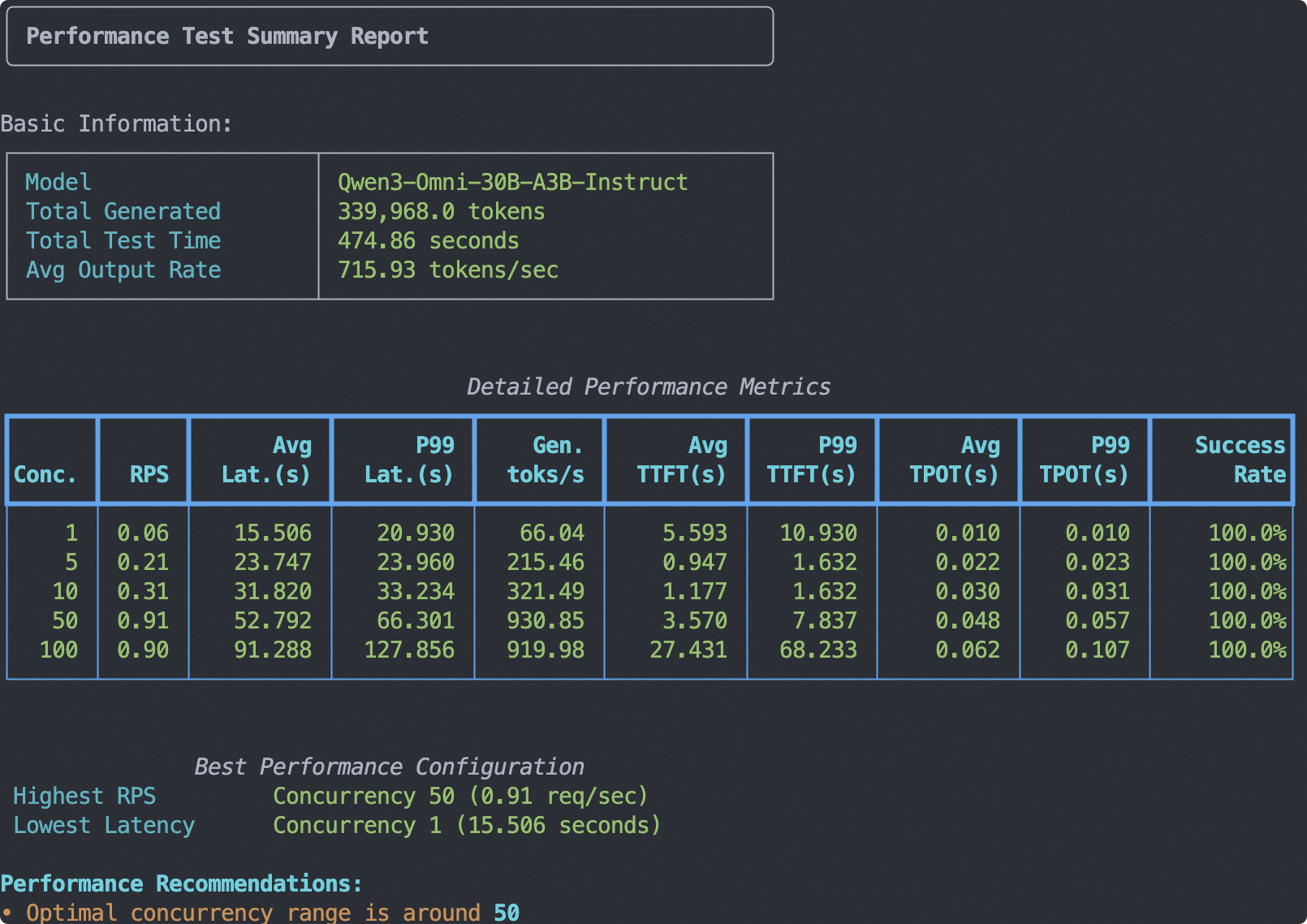
本地模型服务性能评测#
压测命令:
测试环境:A100 80G * 1
输入:1024 tokens文本 + 1张 512*512 图像
输出:1024 tokens
注意:这里使用了Qwen3-30B-A3B-Instruct的tokenizer路径,因为Qwen3-Omni-30B-A3B-Instruct和Qwen3-30B-A3B-Instruct使用相同的文本tokenizer。
evalscope perf \
--model Qwen3-Omni-30B-A3B-Instruct \
--url http://localhost:8801/v1/chat/completions \
--api-key "API_KEY" \
--parallel 1 5 10 50 100 \
--number 2 10 20 100 200 \
--api openai \
--dataset random_vl \
--min-tokens 1024 \
--max-tokens 1024 \
--prefix-length 0 \
--min-prompt-length 1024 \
--max-prompt-length 1024 \
--image-width 512 \
--image-height 512 \
--image-format RGB \
--image-num 1 \
--tokenizer-path Qwen/Qwen3-30B-A3B-Instruct-2507
输出报告如下:
模型能力评测#
下面开始进行模型能力评测流程,我们将在OmniBench上进行评测。OmniBench是一个用于评估多模态模型在文本、图像、音频多种模态上理解能力的基准测试工具。
注意:后续评测流程都基于API模型服务,你可以根据模型推理框架使用步骤拉起模型服务。由于vLLM框架目前(2025.9.25)对于Base64音频的输入支持存在bug,暂时无法进行音频输入的评测。
from evalscope import TaskConfig, run_task
task_cfg = TaskConfig(
model='Qwen3-Omni-30B-A3B-Instruct',
api_url='http://localhost:8801/v1',
api_key='EMPTY',
eval_type='openai_api',
datasets=[
'omni_bench',
],
dataset_args={
'omni_bench': {
'extra_params': {
'use_image': True, # 是否使用图像输入,如果为False,则使用文本替代图像内容。
'use_audio': False, # 是否使用音频输入,如果为False,则使用文本替代音频内容。
}
}
},
eval_batch_size=1,
generation_config={
'max_tokens': 10000, # 最大生成token数,建议设置为较大值避免输出截断
'temperature': 0.0, # 采样温度 (qwen 报告推荐值)
},
limit=100, # 设置为100条数据进行测试
)
run_task(task_cfg=task_cfg)
输出结果如下:
注意:下面的结果是取了100条数据的结果,只用于评测流程测试。在正式评测时需要去掉该限制。
+-----------------------------+------------+----------+----------+-------+---------+---------+
| Model | Dataset | Metric | Subset | Num | Score | Cat.0 |
+=============================+============+==========+==========+=======+=========+=========+
| Qwen3-Omni-30B-A3B-Instruct | omni_bench | mean_acc | default | 100 | 0.44 | default |
+-----------------------------+------------+----------+----------+-------+---------+---------+
更多可用的评测数据集可参考数据集列表。
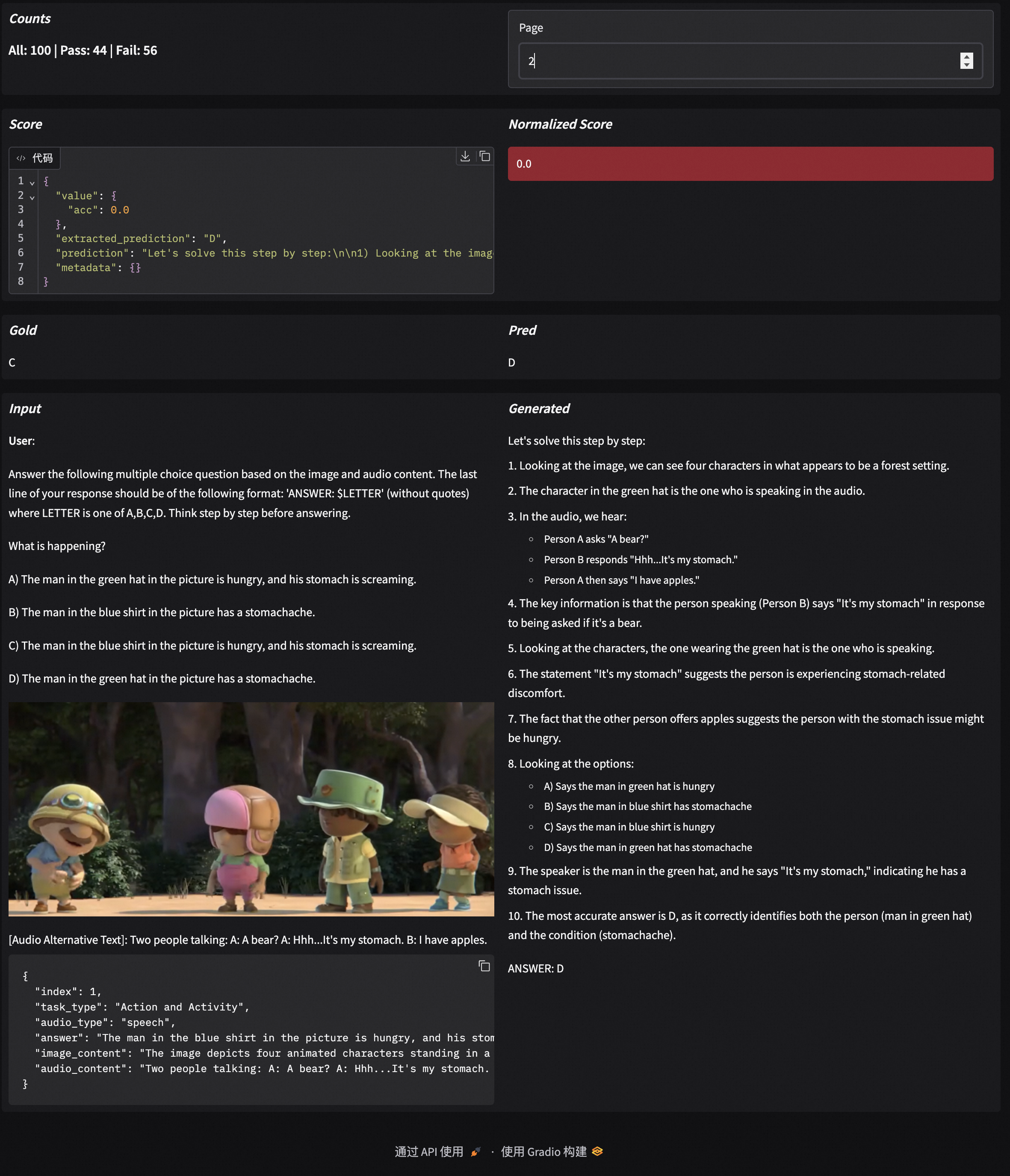
可视化#
EvalScope支持可视化结果,可以查看模型具体的输出。
运行以下命令,可以启动Web 可视化界面:
evalscope service
选择评测报告,点击加载,即可看到模型在每个问题上的输出结果,以及整体答题正确率: