Agent 评测模式#
EvalScope 提供 Agent 评测模式,允许模型在受控的多轮工具调用循环(AgentLoop)中完成评测任务。该模式适合评估模型在工具使用、多步推理、代码修复等代理类场景下的端到端能力,并对每个样本完整记录交互轨迹(AgentTrace)以便复盘与可视化。
概述与基本原理#
启用 Agent 模式有两条路径:
全局开关:在
TaskConfig中设置agent_config = AgentConfig(...),所有基于DefaultDataAdapter的基准(GSM8K、AIME、IFEval 等)会自动改用 AgentLoop 进行推理。基准内置:少数基准(例如
swe_bench_*_agentic)由AgentLoopAdapter子类直接驱动多轮循环,参数走dataset_args.extra_params,不读取全局agent_config。
AgentLoop 在每一轮迭代中执行:生成 → 解析 → 工具调用 → 观察 → 再生成,直到模型主动提交最终答案、或者达到 max_steps 上限。整个流程由三个可插拔组件协同:
组件 |
含义 |
内置实现 |
|---|---|---|
Strategy(策略) |
控制系统提示、消息组织、输出解析、终止判定 |
|
Tool(工具) |
模型可调用的能力,由策略以工具协议或文本块的形式暴露给模型 |
|
Environment(环境) |
工具实际执行所在的隔离沙箱,提供 |
|
每一轮的关键事件(模型生成、工具调用、工具结果、环境命令、错误、nudge、submit)会被结构化记录到 AgentTrace.events 中,并随评测结果一并落盘到 reviews/<model_id>/<dataset>.jsonl 的 agent_trace 字段,供 HTML 报告与 Web 可视化界面回放。
AgentConfig 参数详解#
AgentConfig 定义于 evalscope.api.agent,作为 TaskConfig.agent_config 的取值。
字段 |
类型 |
默认值 |
说明 |
|---|---|---|---|
|
|
|
已注册策略名称,控制模型与循环的交互方式 |
|
|
|
模型可用工具白名单。空列表表示纯多轮对话无工具 |
|
|
|
已注册环境名称。 |
|
|
|
循环迭代硬上限。超过将记录 |
|
|
|
策略构造参数(例如 |
|
|
|
环境构造参数(例如 |
2.1 可选 strategy#
名称 |
说明 |
|---|---|
|
默认策略,使用模型原生 function-calling API。自动注入 |
|
ReAct 风格,注入推理优先的系统提示,同样自动注入 |
|
SWE-bench 工具调用协议,仅允许 |
|
SWE-bench 反引号文本协议,适合不支持 function-calling 的模型 |
2.2 可选 tools#
名称 |
说明 |
是否需要 environment |
|---|---|---|
|
执行 shell 命令,返回 stdout/stderr |
是 |
|
执行 Python 源码,返回 stdout/stderr |
是 |
|
显式提交最终答案; |
否 |
2.3 可选 environment#
名称 |
说明 |
|---|---|
|
|
|
|
2.4 environment_extra 子字段#
local 环境:
working_dir(str):工作目录env_vars(dict[str, str]):注入的环境变量
docker 环境:
image(str):Docker 镜像名(例如python:3.11-slim)timeout(float):单次命令超时时间(秒)environment(dict[str, str]):容器内环境变量
小技巧
启用 environment='docker' 时复用了 沙箱环境 介绍的 ms-enclave 基础设施。请先完成沙箱依赖与 Docker 安装,建议同时通过 TaskConfig.sandbox = SandboxTaskConfig(enabled=True, engine='docker') 显式开启沙箱(详见沙箱文档)。
2.5 extra 子字段#
system_prompt(str):覆盖策略默认的系统提示词,例如让模型优先调用python_exec进行计算。
通用 Benchmark 走 Agent 模式#
3.1 用例 A:GSM8K + function_calling + python_exec + Docker#
让模型在求解 GSM8K 数学题时强制调用 python_exec 工具进行计算验证,工具运行在 Docker 容器中。
from dotenv import dotenv_values
from evalscope import TaskConfig, run_task
from evalscope.api.agent import AgentConfig
env = dotenv_values('.env')
task_config = TaskConfig(
model='qwen-plus',
api_url='https://dashscope.aliyuncs.com/compatible-mode/v1',
api_key=env.get('DASHSCOPE_API_KEY'),
eval_type='openai_api',
datasets=['gsm8k'],
dataset_args={'gsm8k': {'few_shot_num': 0}},
eval_batch_size=5,
limit=5,
generation_config={
'max_tokens': 2048,
'temperature': 0.7,
'parallel_tool_calls': True,
},
agent_config=AgentConfig(
strategy='function_calling',
tools=['python_exec'],
environment='docker',
environment_extra={'image': 'python:3.11-slim', 'timeout': 60},
max_steps=5,
extra={
'system_prompt': (
'You are a math solver. '
'Use the python_exec tool to verify your calculations.'
),
},
),
)
run_task(task_config)
执行成功后,reviews/qwen-plus/gsm8k_*.jsonl 中每条记录的 agent_trace 字段都会满足:
agent_trace.strategy == 'function_calling'agent_trace.environment == 'docker'agent_trace.events至少包含model_generate,模型实际调用工具时会出现成对的tool_call/tool_result。
3.2 用例 B:AIME + react + bash + local#
ReAct 策略让模型先推理再行动,并允许其在本地子进程沙箱中调用 bash。
from dotenv import dotenv_values
from evalscope import TaskConfig, run_task
from evalscope.api.agent import AgentConfig
env = dotenv_values('.env')
task_config = TaskConfig(
model='qwen-plus',
api_url='https://dashscope.aliyuncs.com/compatible-mode/v1',
api_key=env.get('DASHSCOPE_API_KEY'),
eval_type='openai_api',
datasets=['aime26'],
dataset_args={'aime26': {'few_shot_num': 0}},
eval_batch_size=5,
limit=5,
generation_config={
'max_tokens': 2048,
'temperature': 0.7,
'parallel_tool_calls': True,
},
agent_config=AgentConfig(
strategy='react',
tools=['bash'],
environment='local',
max_steps=10,
),
)
run_task(task_config)
预期产出:
agent_trace.strategy == 'react'、agent_trace.environment == 'local'agent_trace.events至少包含model_generate;当模型调用工具时会出现成对的tool_call/tool_result,未调用工具时可能出现一次nudge。
小技巧
local环境无文件系统隔离,请仅用于开发调试。生产场景请改用docker。agent_config同样支持以字典形式传入,TaskConfig 会自动转换为AgentConfig实例。
SWE-bench Agentic 用例#
swe_bench_*_agentic 系列基准(swe_bench_verified_agentic、swe_bench_verified_mini_agentic、swe_bench_lite_agentic)由 AgentLoopAdapter 子类直接驱动 AgentLoop,不读取 TaskConfig.agent_config。所有循环参数通过 dataset_args 的 extra_params 传入。
4.1 extra_params 参数表#
参数 |
类型 |
默认值 |
可选值 |
说明 |
|---|---|---|---|---|
|
|
|
|
代理协议。 |
|
|
|
- |
单样本最大代理步数 |
|
|
|
- |
单条 bash 命令默认超时时间(秒) |
|
|
|
- |
容器内工作目录 |
|
|
|
- |
是否在本地为每个样本构建 Docker 镜像 |
|
|
|
- |
构建前是否优先尝试拉取远端镜像 |
|
|
|
|
强制指定镜像构建/拉取架构。空字符串表示沿用本机架构 |
4.2 完整运行示例#
下面的示例对应 tests/benchmark/test_agent.py 中 swe_bench_verified_mini_agentic 的运行配置,对前 3 个样本进行评测。
from dotenv import dotenv_values
from evalscope import TaskConfig, run_task
env = dotenv_values('.env')
task_config = TaskConfig(
model='qwen-plus',
api_url='https://dashscope.aliyuncs.com/compatible-mode/v1',
api_key=env.get('DASHSCOPE_API_KEY'),
eval_type='openai_api',
datasets=['swe_bench_verified_mini_agentic'],
dataset_args={
'swe_bench_verified_mini_agentic': {
'extra_params': {
'action_protocol': 'toolcall',
'max_steps': 250,
'command_timeout': 60.0,
'working_dir': '/testbed',
'build_docker_images': True,
'pull_remote_images_if_available': True,
},
},
},
eval_batch_size=2,
limit=3,
generation_config={
'max_tokens': 4096,
'temperature': 0.0,
},
)
run_task(task_config)
重要
前置依赖:
pip install evalscope[swe_bench],并确保本机已安装并启动 Docker。如果同时配置了
agent_config,该全局配置会被 swe_bench agentic 基准忽略,请通过extra_params调整循环参数。关于沙箱镜像与远端管理器,请阅读 沙箱环境使用。
数据集说明请见 SWE-bench benchmark 文档。
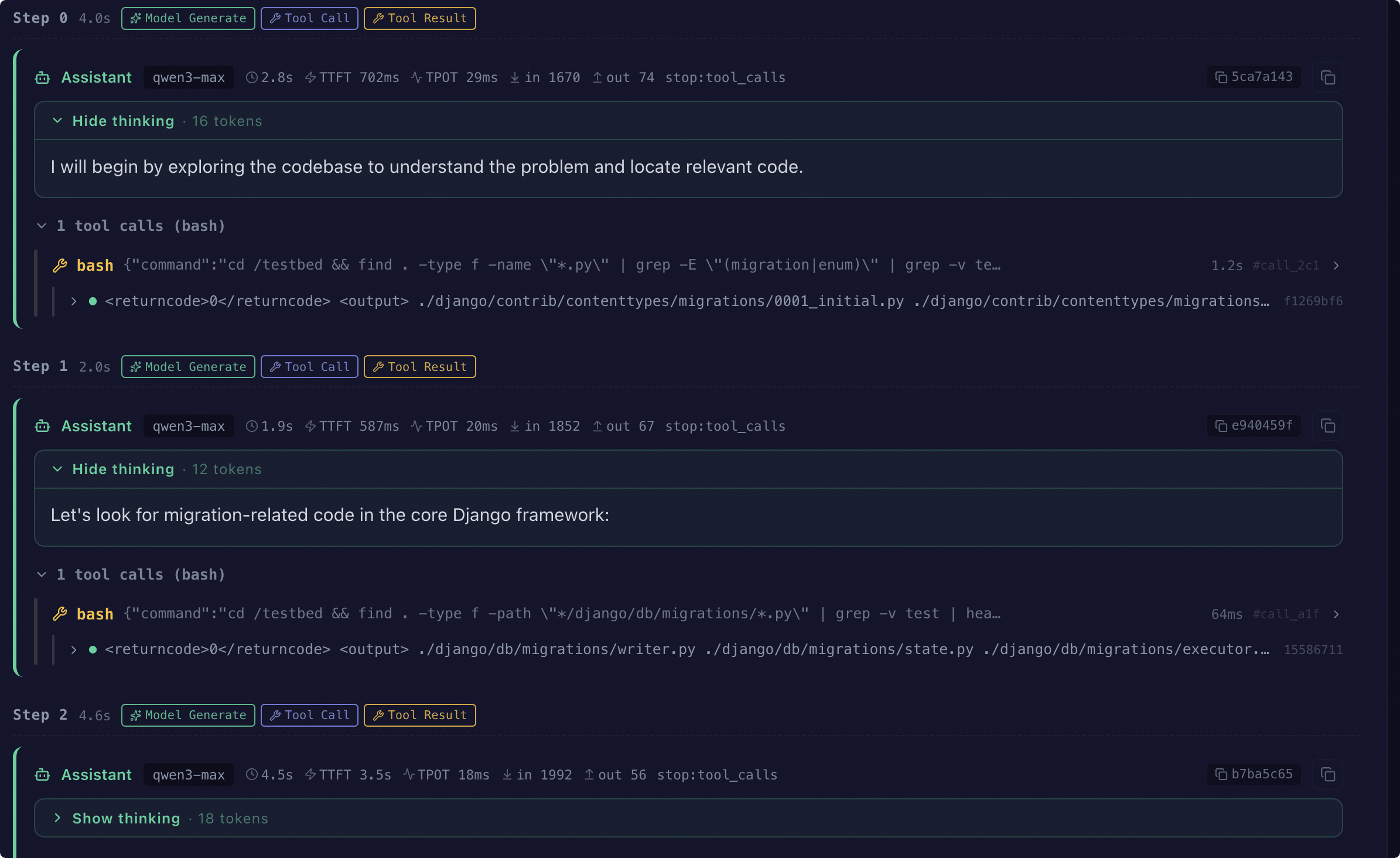
Trace 可视化#
启用 Agent 模式后,每条样本的评测结果会附带 agent_trace 字段。通过 EvalScope 的 Web 可视化界面可以按步骤回放完整的代理交互轨迹:
启动 Web 服务:
evalscope service --outputs ./outputs在仪表盘中选中目标评测报告,进入「单模型评测详情 → 预测」标签
系统检测到
agent_trace后,会按step自动分组渲染 Agent Trace 视图
视图中按时间顺序呈现以下核心元素:
助手回复:每一步的模型输出、推理过程、本步延迟与 token 用量
工具调用与工具结果:聚合显示同一步内的多次 tool_call 与对应观察
环境命令:bash / python_exec 实际下发到沙箱的命令行
Nudge / Error 提示:模型未调用工具时的系统提醒,以及解析错误或工具异常
事件 pill:紧凑展示
model_generate / tool_call / tool_result / env_exec / nudge / error / submit事件,附带耗时与 token 数
参见
评测可视化的整体使用说明(仪表盘、报告对比、预测视图等)请参考 可视化。
常见问题#
Q1:何时使用全局 agent_config,何时依赖基准内置 AgentLoop?
想让常规基准(GSM8K、AIME、IFEval、HLE 等)变成多轮工具调用形式 → 设置
TaskConfig.agent_config。评测 SWE-bench agentic、Terminal-Bench 等天生属于代理任务的基准 → 直接运行对应数据集,调节
dataset_args.extra_params,不需要也不要设置agent_config(会被忽略)。
Q2:模型完全没有调用工具该如何排查?
确认
agent_config.tools中的工具名拼写正确(参见第 2.2 节列表)。确认所选模型支持 function-calling;不支持的模型可改用
swe_bench_backticks等文本协议策略。查看
agent_trace.events是否出现nudge(系统已提醒模型调用工具但仍未调用)或error(解析 / 工具执行报错)。通过
extra={'system_prompt': '...'}显式要求模型调用某个工具。
Q3:max_steps 应该设置多少?
数学 / 简单 QA 类基准:
3–10通常足够。代码修复 / SWE-bench 类基准:建议沿用默认
250,过低可能导致大量max_steps_exceeded。
Q4:使用 environment='docker' 报 Docker 相关错误?
确认本机已安装并启动 Docker(参见 沙箱环境使用)。
镜像首次拉取失败时可手动
docker pull <image>后再运行评测。远端 Docker 守护进程可通过
TaskConfig.sandbox.manager_config = {'base_url': 'http://<host>:<port>'}接入。