可视化#
EvalScope 提供了基于 Web 的可视化工具,支持对单个或多个模型的评测结果进行深入分析和对比,兼容数据集混合评测的展示,并支持在线评测任务提交与监控。
重要
该可视化工具专用于展示模型评测结果,不适用于模型压测结果。如需可视化压测报告,请参考压测结果可视化指南。
安装与启动#
1. 安装依赖#
安装可视化所需的依赖库:
pip install 'evalscope[service]' -U
备注
可视化功能需要 evalscope>=0.10.0 生成的评测报告。若版本过低,请先升级并重新运行评测。
2. 启动服务#
运行以下命令启动可视化 Web 服务:
evalscope service
服务启动后,在浏览器中打开打印的 Dashboard URL(默认为 http://127.0.0.1:9000)即可访问。
支持的命令行参数如下:
--host:服务器监听地址,默认为0.0.0.0。--port:服务器端口,默认为9000。--outputs:指定评测报告所在的根目录,默认为./outputs。--debug:启用调试模式。
3. 界面设置#
Web 界面顶部导航栏右侧提供以下快捷操作:
语言切换:点击语言按钮可在中文和 English 之间切换界面语言。
主题切换:点击日/月图标可在浅色模式和深色模式之间切换。
快速体验#
我们提供了一份包含多个模型和数据集的评测样例,让您能快速体验可视化功能:
git clone https://github.com/modelscope/evalscope
evalscope service --outputs examples/viz
该样例包含了 qwen-plus 和 qwen3-max 模型在 GSM8K、GPQA、IFEval、iQuiz 等数据集上的评测结果。
功能介绍#
仪表盘#
仪表盘是进入可视化工具后的首页,提供评测结果的宏观概览。
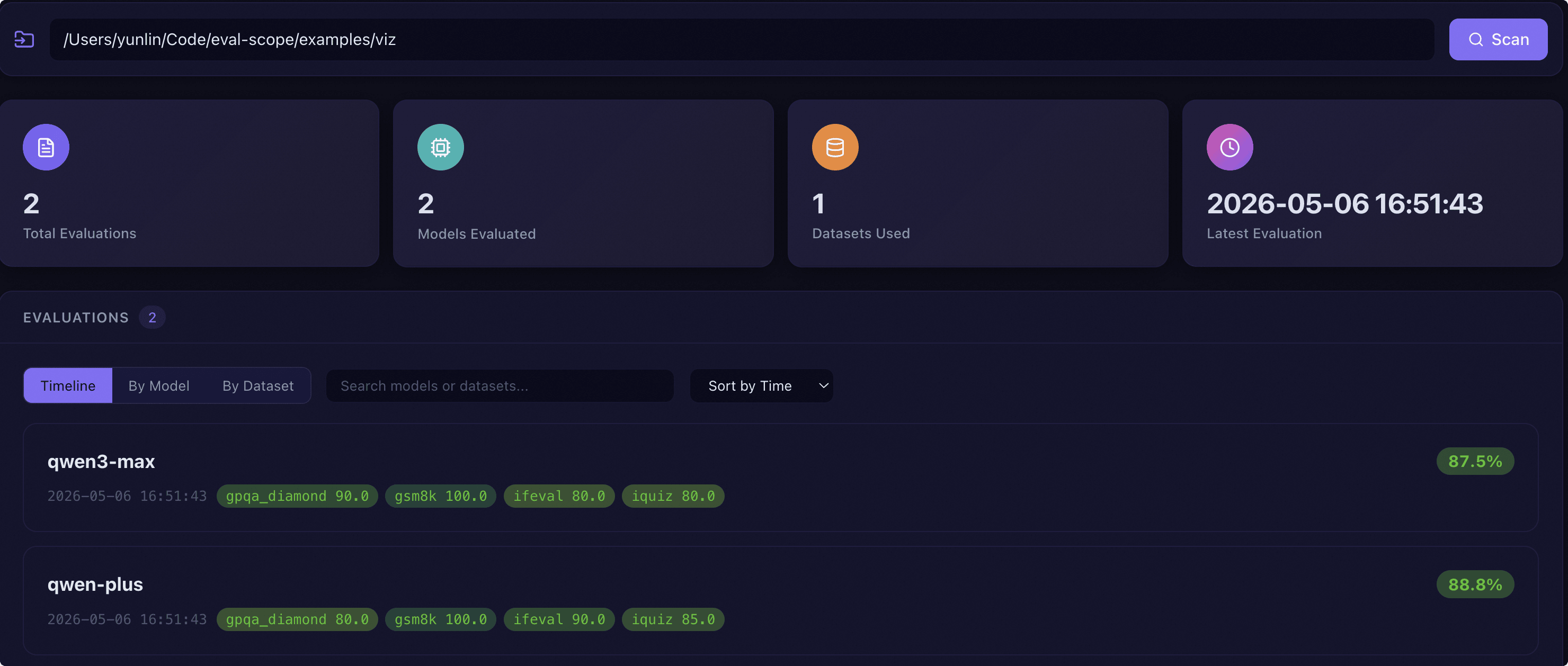
目录扫描:在页面顶部的路径栏中输入评测报告所在的根目录,点击扫描按钮即可自动发现该目录下的所有评测报告。
KPI 卡片:扫描完成后,页面显示四张关键指标卡片:
评测总数:已发现的评测报告数量,点击可切换到时间线视图。
评测模型数:涉及的不同模型数量,点击可切换到按模型分组视图。
数据集数:涉及的不同数据集数量,点击可切换到按数据集分组视图。
最近评测时间:最新一次评测的时间戳,点击可跳转到该报告详情。
评测列表:支持三种视图模式切换:
时间线视图:按时间顺序展示每条评测记录,每张卡片显示模型名称、综合得分、时间戳和各数据集得分标签。
按模型分组:将评测记录按模型名称分组折叠展示,显示每组最佳得分和评测次数。
按数据集分组:将评测记录按数据集名称分组折叠展示,显示每组最佳得分和评测次数。
此外,列表区域还提供搜索框(按模型名或数据集名搜索)和排序选项(按时间、得分、模型名排序)。
评测报告列表#
报告列表页提供更精细的报告管理和筛选功能,支持多选报告进行对比分析。
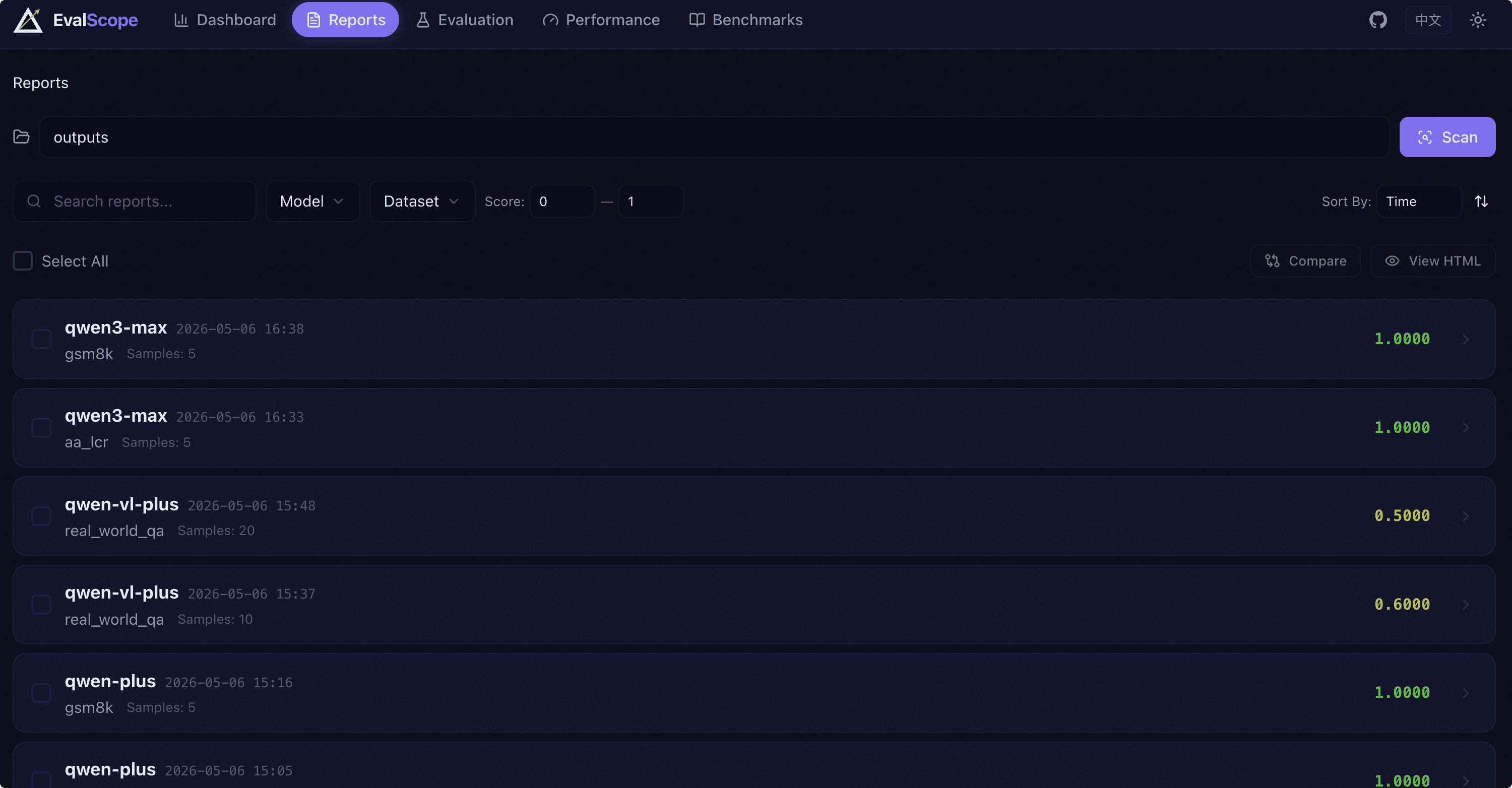
筛选条件:提供以下筛选维度:
关键词搜索:按报告名称模糊搜索。
模型筛选:多选下拉框,按模型名称过滤。
数据集筛选:多选下拉框,按数据集名称过滤。
得分范围:设置最低和最高得分区间。
排序方式:按时间、得分、模型名、数据集名排序,支持升序/降序切换。
多选与对比:每张报告卡片左侧有复选框,选中后可执行以下操作:
对比:选中 2-3 份报告后,点击对比按钮进入多模型对比页面。
查看 HTML 报告:选中 1 份报告后,可在浏览器新标签页中打开该报告的 HTML 版本。
分页:报告列表支持分页浏览,每页展示 20 条记录。
单模型评测详情#
点击任意评测报告可进入详情页,查看单个模型在各数据集上的详细表现。详情页由报告头部、数据集导航和三个功能标签页组成。
概览标签#
报告头部展示模型名称、关联数据集列表(可点击切换)、综合得分和样本总数,并提供查看 HTML 报告和返回列表的快捷按钮。
概览标签提供模型在各数据集上的整体表现汇总:
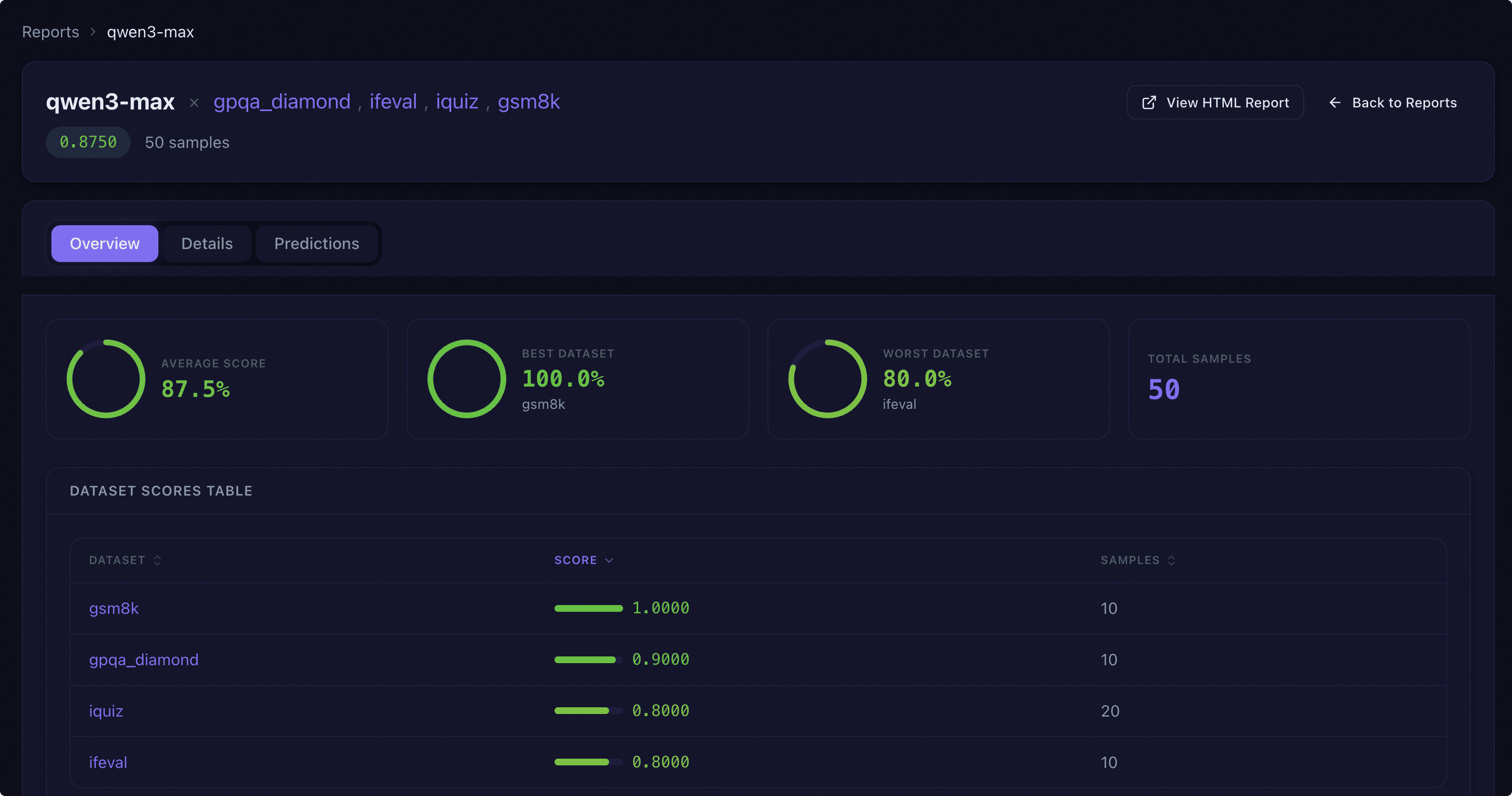
统计概览:以环形进度图和数字卡片展示平均得分、最佳/最差数据集及其得分、总样本数。
数据集得分表:可排序表格,列出每个数据集的名称、得分(含进度条和数值)和样本数。点击数据集名称可跳转到该数据集的详情标签。
雷达图:以雷达图形式直观展示模型在各数据集上的能力维度分布。
任务配置:可折叠区域,以 JSON 查看器展示本次评测的任务配置信息。
详情标签#
详情标签深入展示选定数据集的子集得分和分析结果:
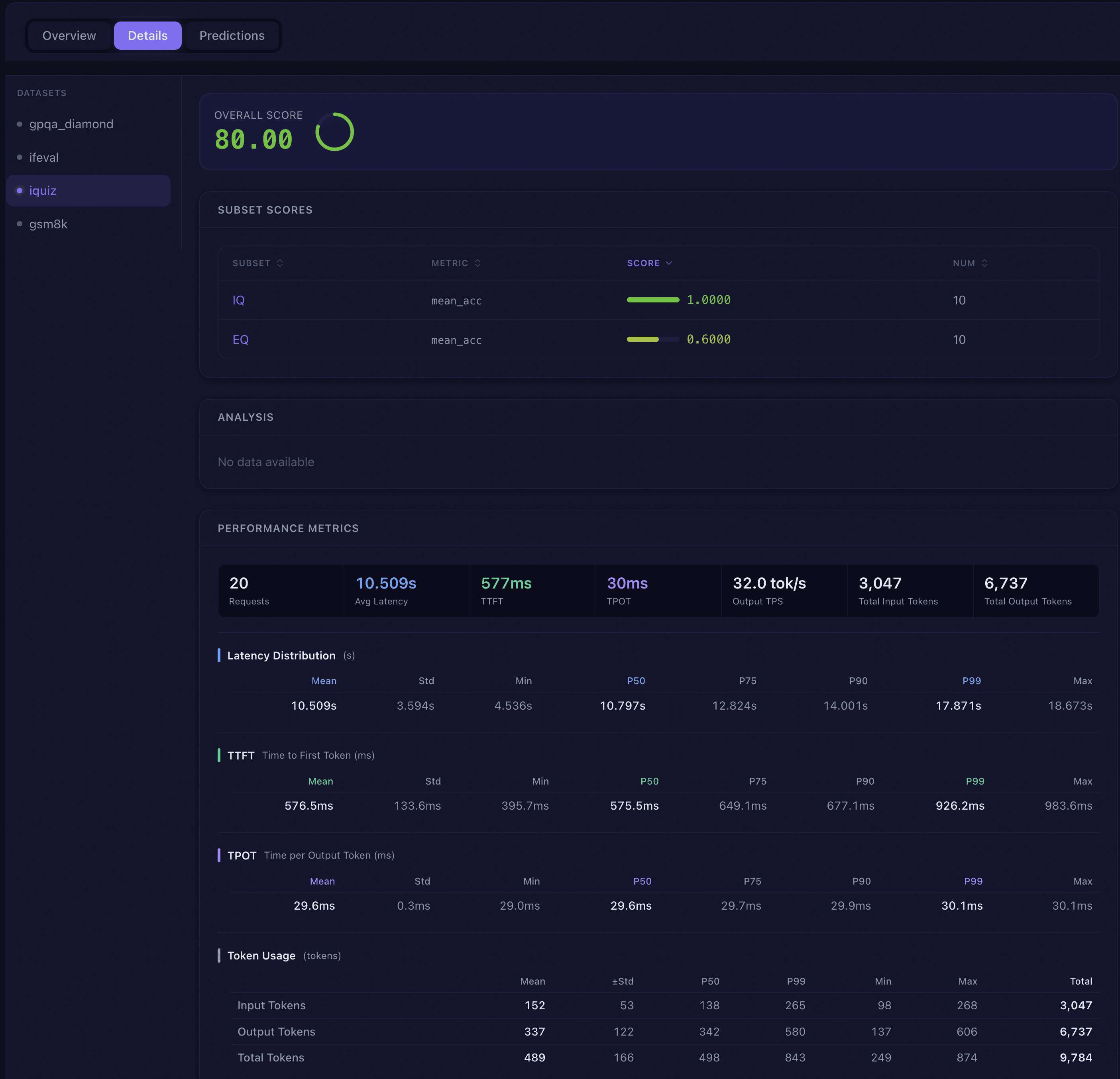
综合得分:以大号数字和环形进度图展示该数据集的整体得分。
子集得分表:可排序表格,列出每个子集的名称、指标(如存在)、得分和样本数。点击子集名称可直接跳转到预测标签中该子集的样本浏览。
AI 分析:以 Markdown 格式渲染的智能分析报告,对该数据集的表现进行解读。
性能指标:当评测包含性能数据时,展示延迟分布(含百分位表)、TTFT(首 Token 时间)、TPOT(每 Token 时间)和 Token 用量统计。
预测标签#
预测标签逐条浏览每个样本的详细预测结果,是最细粒度的分析工具:
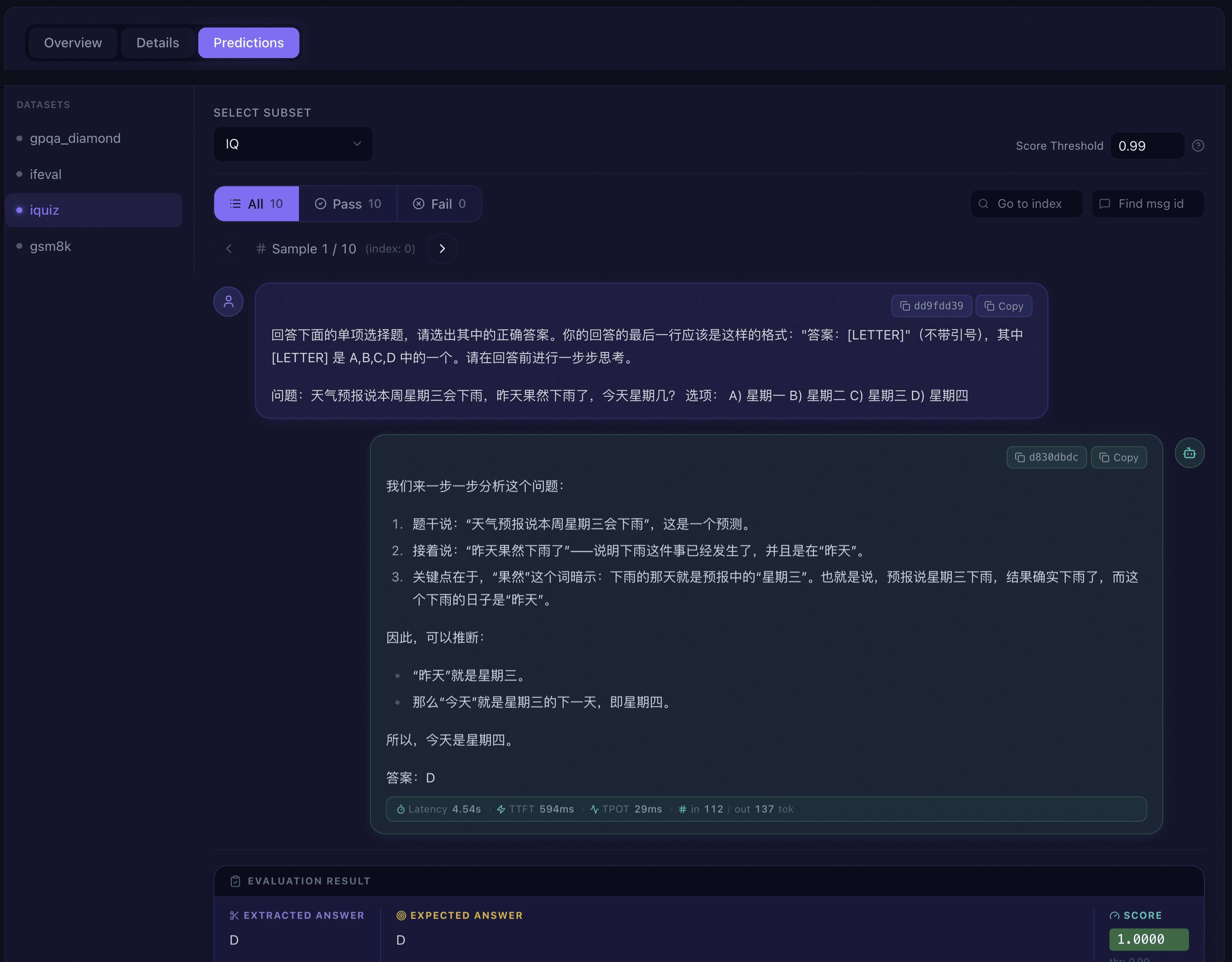
筛选与导航:
子集选择器:下拉选择当前数据集的子集。
得分阈值:设置判定通过/失败的分数阈值,默认 0.99。
通过状态过滤:All / Pass / Fail 三个按钮快速筛选样本,每个按钮显示对应数量。
样本搜索:支持按样本索引号(Index)和消息 ID(Message ID)精确搜索跳转。
样本翻页:左右箭头按钮或键盘方向键逐条浏览,显示当前页码和总页数。
对话视图:每个样本以聊天气泡形式展示,支持以下内容类型:
系统提示:可折叠的顶部横幅,展示 System Prompt 内容。
用户消息:蓝色气泡,支持文本、图片(点击可放大查看)、音频等富媒体内容。多轮对话时显示轮次标签。
助手回复:绿色气泡,支持文本、推理过程(可折叠)、工具调用(可折叠)和性能指标。多轮对话时显示轮次标签。
工具结果:可折叠的工具返回结果区域。
消息 ID:每条消息右上角显示可复制的消息 ID 标签。
内容复制:每条消息提供一键复制按钮。
评测结果面板:对话视图下方展示评测判定详情:
提取答案:模型输出中提取的预测答案(与生成内容不同时显示)。
标准答案:预期的正确答案。
得分:数值得分及通过/失败标识。
评分详情:可折叠的 JSON 视图,展示评分计算的完整信息。
元数据:可折叠的 JSON 视图,展示样本的附加元信息。
小技巧
当评测启用 Agent 评测 时,预测视图会自动检测样本的 agent_trace 并按 step 分组渲染 Agent Trace 视图(含工具调用、环境命令、nudge、错误等)。完整说明与示意图见 Agent 评测 → Trace 可视化。
数据集导航#
在详情和预测标签中,左侧提供数据集导航侧边栏(移动端为顶部横向滚动条),可快速切换当前查看的数据集。
多模型对比#
在报告列表页选中 2-3 份报告后点击“对比按钮”,即可进入多模型对比页面。对比页面支持最多 3 个模型的横向对比分析。
得分对比#
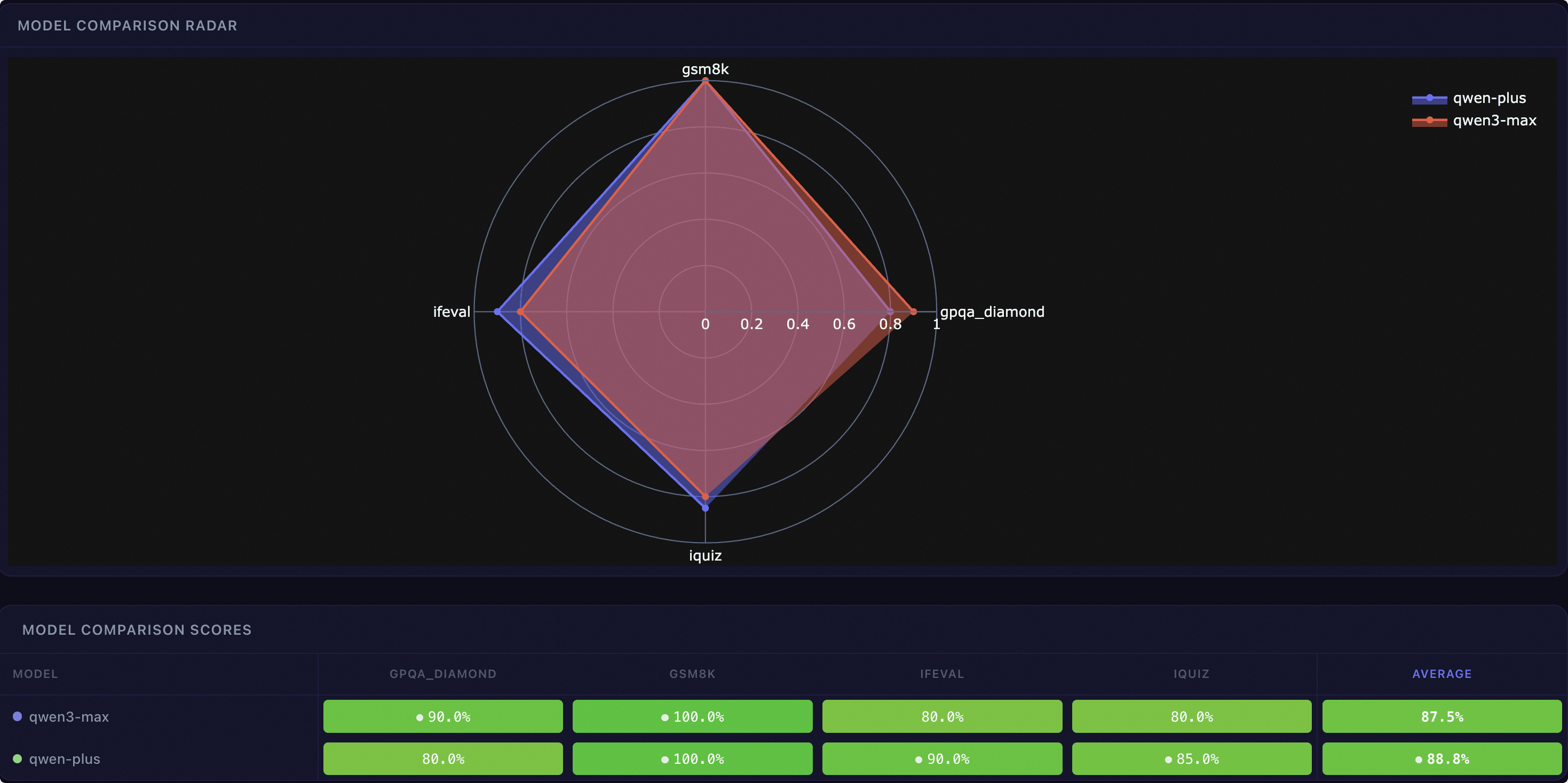
雷达图:以多边形雷达图直观展示各模型在不同数据集上的能力维度对比。
得分对比表:以数据集为行、模型为列的表格,每个单元格以颜色编码显示得分百分比,最高分标记高亮。表格底部计算各模型的平均得分。
预测对比#
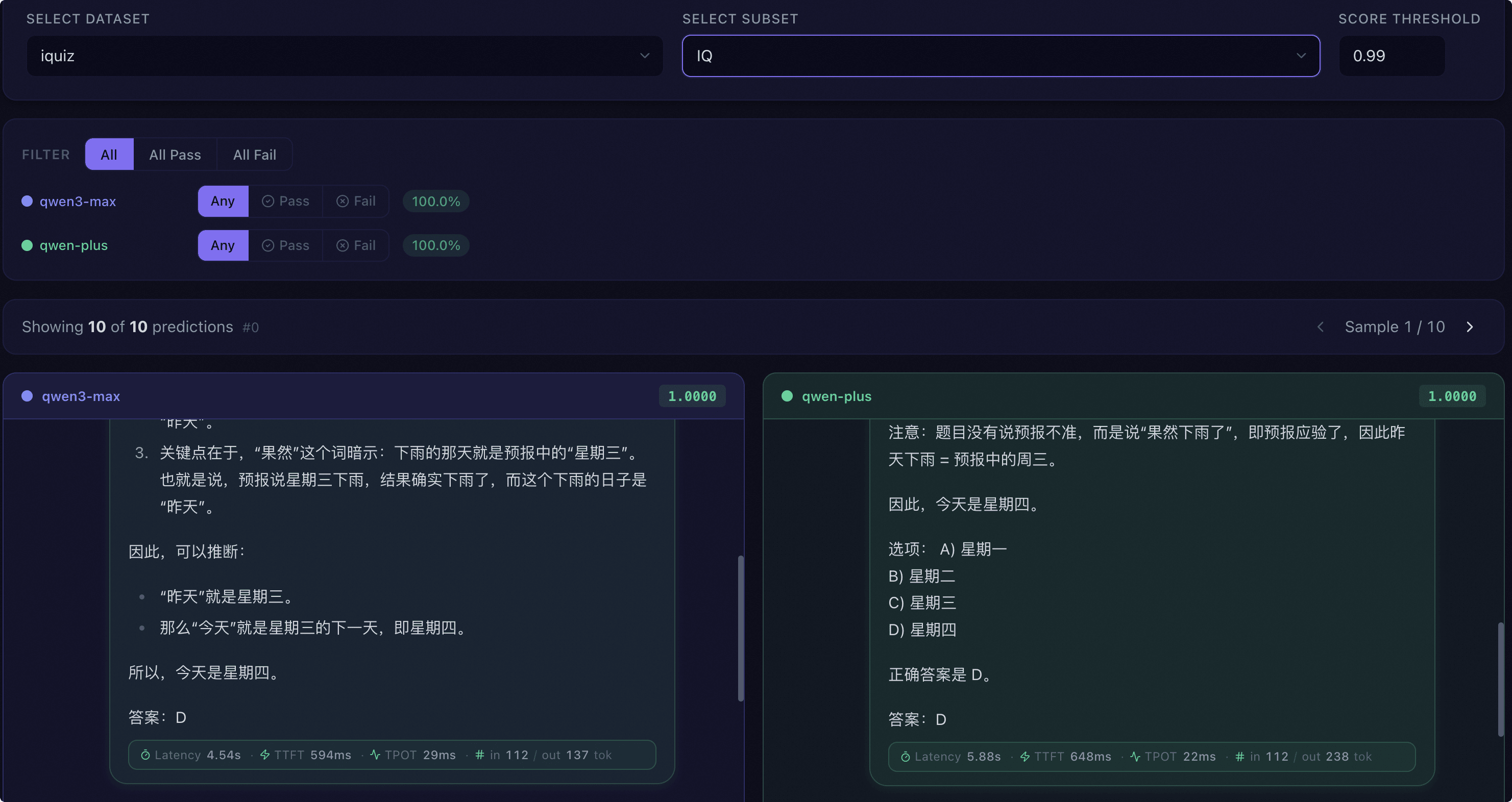
数据集与子集选择:选择共同数据集和子集进行逐样本对比。
得分阈值:设置通过/失败的判定阈值。
按模型过滤:每个模型独立设置 Any / Pass / Fail 三态过滤器,支持 All Pass、All Fail 等快捷预设。
通过率标签:每个模型显示当前过滤条件下的通过率百分比。
并排对话视图:以多列布局并排展示同一题目下各模型的预测结果,每列以不同颜色标识,顶部显示模型名称和得分。支持键盘方向键翻页。
统计栏:显示过滤后的样本数和总样本数,并提供翻页控件。
模型管理#
对比页面顶部的模型管理区域支持以下操作:
查看已选模型:以标签形式展示当前参与对比的模型。
移除模型:点击标签上的移除按钮可移除某个模型(至少保留 2 个)。
添加模型:点击添加按钮输入报告名称添加新模型(最多 3 个)。
评测基准浏览#
评测基准页面提供 EvalScope 支持的所有评测数据集的浏览与检索功能。
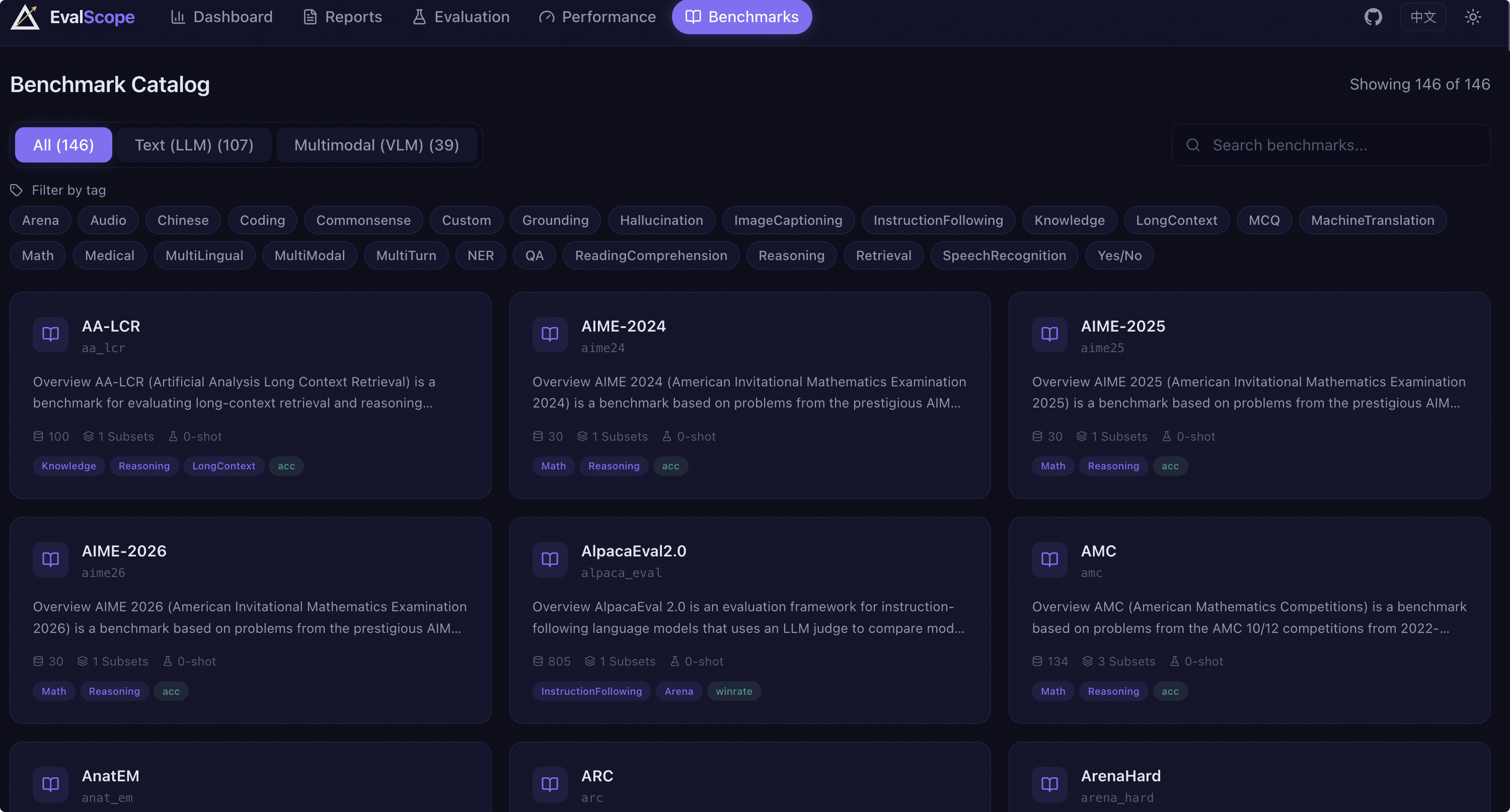
分类标签:通过 All / Text / Multimodal 标签切换查看文本类或多模态类数据集。
关键词搜索:按名称或描述搜索数据集。
标签筛选:点击标签按钮按能力维度(如 math、reasoning、code 等)筛选数据集。
数据集卡片:每张卡片展示数据集名称、标识符、描述摘要、样本数、子集数、Few-shot 数、标签和指标。
详情弹窗:点击卡片可打开模态窗口,展示数据集的完整 Markdown 描述、论文链接等详细信息。
在线评测与压测#
Web 界面支持直接提交评测和压测任务,无需命令行操作。
评测任务#
评测任务页面提供配置表单和任务监控面板:
配置表单:填写模型、数据集、生成参数等评测配置后提交任务。
任务监控:实时显示任务进度条和运行日志,任务完成后可直接查看评测报告。
压测任务#
压测任务页面提供配置表单和任务监控面板:
配置表单:填写模型连接信息和压测参数后提交任务。
任务监控:实时显示压测进度和日志,任务完成后可直接查看压测报告。