Agent 评测#
EvalScope 提供 Agent 评测,允许模型或成品 Agent CLI 在受控的多轮工具调用循环中完成评测任务,并把完整交互过程录制下来,供 Web 界面回放与复盘。
两种模式#
模式 |
适用场景 |
文档 |
|---|---|---|
内置 AgentLoop |
给常规 benchmark(GSM8K、AIME、SWE-bench 等)套上多轮工具调用循环,评测模型自身的工具使用能力 |
|
外部 Agent Bridge |
直接评测 Claude Code / Codex 等成品 Agent CLI,EvalScope 把 CLI 的 LLM 请求转发到你的评测模型 |
两种模式都通过 TaskConfig.agent_config 配置,一次评测只能选一种。
Trace 可视化#
启用 Agent 评测后,每条样本都会附带一条 Trace。通过 Web 界面可以按步骤回放完整交互过程:
启动 Web 服务:
evalscope service --outputs ./outputs在仪表盘里选目标报告,进入「单模型评测详情 → 预测」标签
检测到 Trace 后,会按
step自动渲染 Agent Trace 视图
视图按时间顺序呈现:
每一步的模型回复(含推理过程、延迟与 token 用量)
工具调用与观察结果(聚合显示同一步内的多次调用)
沙箱内执行的命令(bash、python_exec 或外部 CLI 实际下发的命令行)
系统提醒与异常(模型未调用工具时的 nudge、解析或工具执行错误)
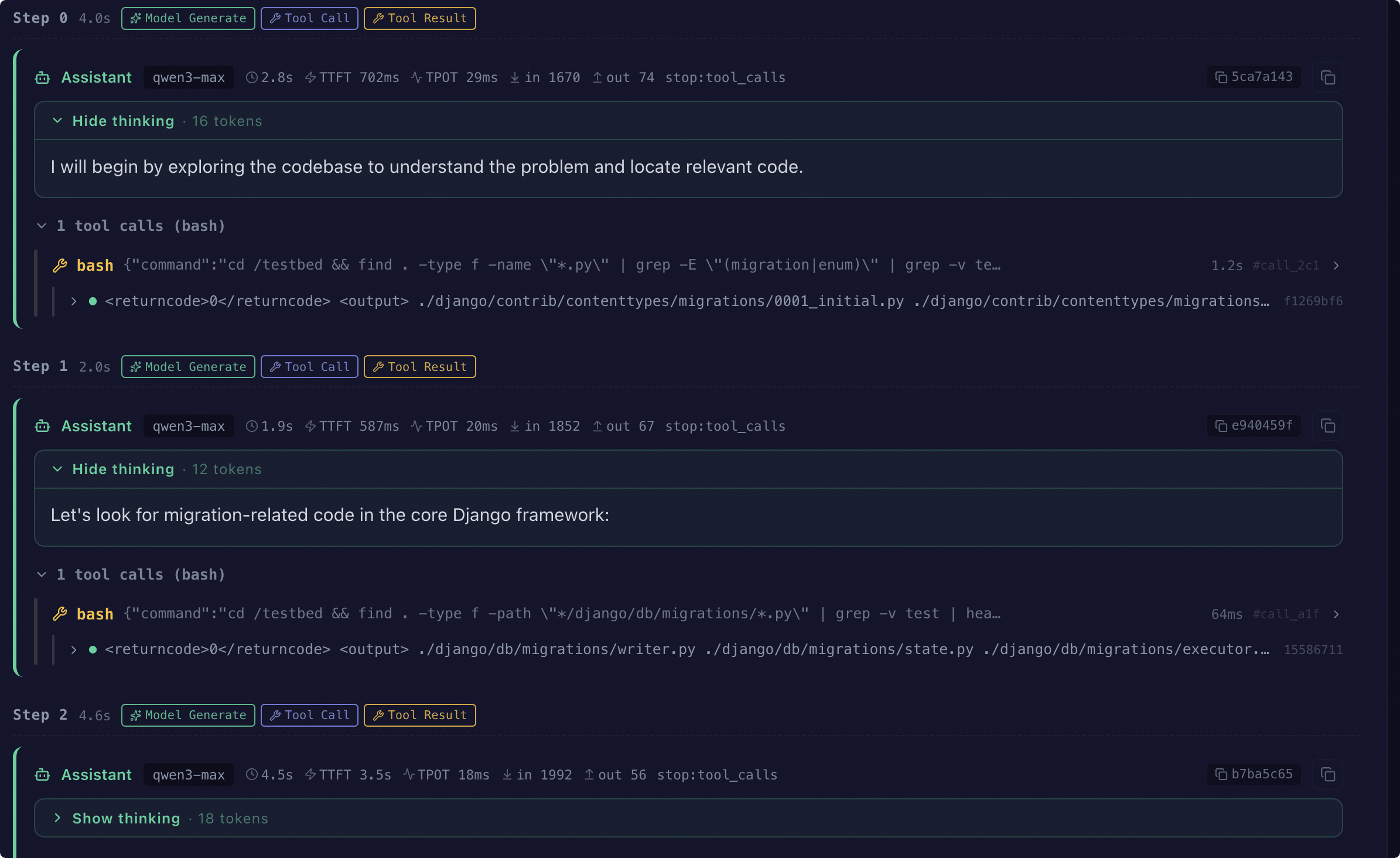
参见
Web 仪表盘的整体使用说明(报告对比、预测视图等)请参考 可视化。
常见问题#
何时使用 agent_config,何时依赖基准内置 AgentLoop?
想让常规基准(GSM8K、AIME、IFEval、HLE 等)变成多轮工具调用形式 → 在
TaskConfig.agent_config设置AgentConfig或ExternalAgentConfig。评测 SWE-bench agentic、Terminal-Bench 等天生属于代理任务的基准 → 直接运行对应数据集,通过
dataset_args.extra_params调参,不需要也不要设置agent_config(会被忽略)。swe_bench_pro等基准会带自己的样本级环境,可与 外部 Agent Bridge 组合,留空environment即可。
其他模式特定的常见问题请见各自子页:内置 AgentLoop FAQ · 外部 Agent Bridge FAQ。